



A significant challenge in the field of artificial intelligence, particularly in generative modeling, is understanding how diffusion models can effectively learn and generate high-dimensional data distributions. Despite their empirical success, the theoretical mechanisms that enable diffusion models to avoid the curse of dimensionality—where the number of required samples increases exponentially with data dimension—remain poorly understood. Addressing this challenge is crucial for advancing generative models in AI, particularly for applications in image generation, where the ability to efficiently learn from high-dimensional data is paramount.

Current methods for learning high-dimensional data distributions, particularly through diffusion models, involve estimating the score function, which is the gradient of the logarithm of the probability density function. These models typically operate through a two-step process: first, incrementally adding Gaussian noise to the data, and then progressively removing this noise via a reverse process to approximate the data distribution. While these methods have achieved significant empirical success, they struggle to explain why diffusion models require fewer samples than theoretically expected to accurately learn complex data distributions. Additionally, these models often face issues with over-parameterization, leading to memorization rather than generalization, which limits their applicability to broader real-world scenarios.

Researchers from the University of Michigan and the University of California present a novel approach that models the underlying data distribution as a mixture of low-rank Gaussians (MoLRG). This method is motivated by key empirical observations: the low intrinsic dimensionality of image data, the manifold structure of image data as a union of manifolds, and the low-rank nature of the denoising autoencoder in diffusion models. By parameterizing the denoising autoencoder as a low-rank model, it is shown that optimizing the training loss of diffusion models is equivalent to solving a subspace clustering problem. This innovative framework addresses the shortcomings of existing methods by providing a theoretical explanation for the efficiency of diffusion models in high-dimensional spaces, demonstrating that the number of required samples scales linearly with the intrinsic dimension of the data. This contribution represents a significant advancement in understanding the generalization capabilities of diffusion models.

The data distribution is modeled as a mixture of low-rank Gaussians, with data points generated from multiple Gaussian distributions characterized by zero mean and low-rank covariance matrices. A key technical innovation lies in the parameterization of the denoising autoencoder (DAE), which is expressed as:
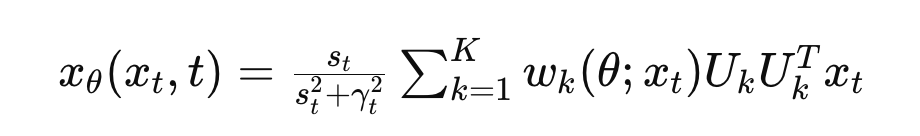
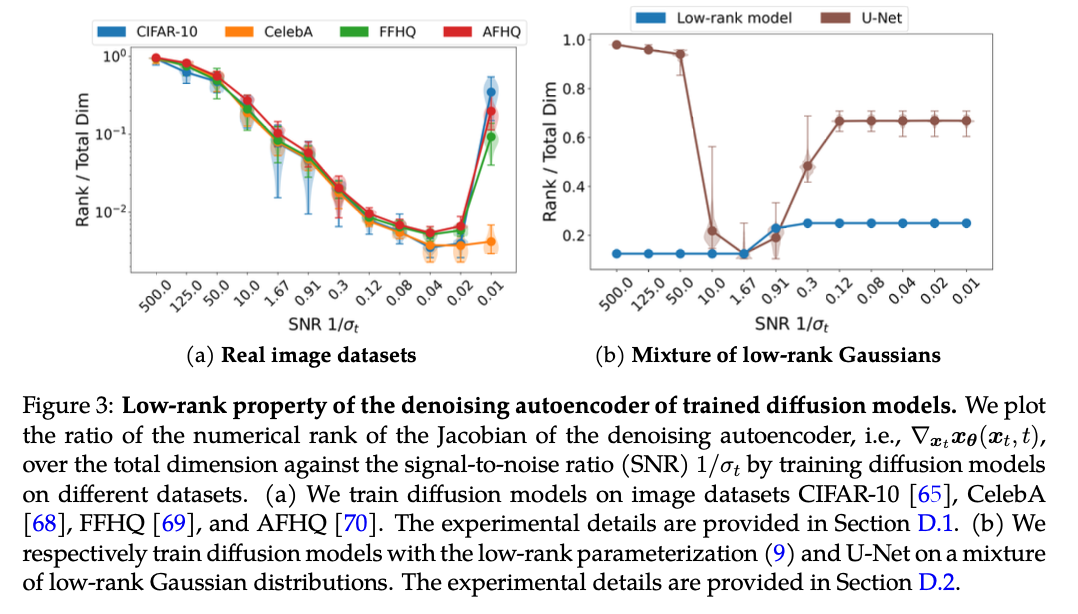
Here, Uk represents orthonormal basis matrices for each Gaussian component, and the weights wk(θ;xt) are soft-max functions based on the projection of xt onto the subspaces defined by Uk. This low-rank parameterization effectively captures the intrinsic low-dimensionality of the data, allowing the diffusion model to efficiently learn the underlying distribution. Empirical validation is provided through experiments on synthetic and real image datasets, where the DAE exhibits consistent low-rank properties, reinforcing the theoretical assumptions.
The approach demonstrates its effectiveness in learning high-dimensional data distributions while overcoming the curse of dimensionality. By modeling the data as a mixture of low-rank Gaussians, the method efficiently captures the underlying distribution, requiring a number of samples that scales linearly with the data’s intrinsic dimension. Experimental validation shows significant improvements in accuracy and sample efficiency across various datasets. The model consistently generalizes well beyond the training data, achieving a high generalization score, which indicates successful learning of the true distribution rather than mere memorization. These outcomes highlight the robustness and efficiency of the model in dealing with complex, high-dimensional data, marking a valuable contribution to AI research.
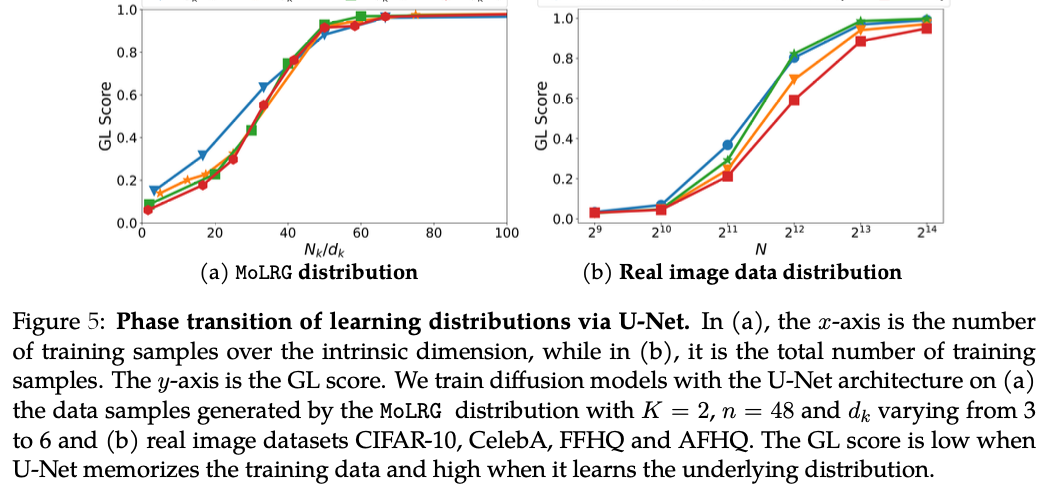
This research makes a significant contribution to AI by providing a theoretical framework that explains how diffusion models can efficiently learn high-dimensional data distributions. The researchers address the core challenge of avoiding the curse of dimensionality by modeling the data distribution as a mixture of low-rank Gaussians and parameterizing the denoising autoencoder to capture the data’s low-dimensional structure. Extensive experiments validate the method, demonstrating that it can learn the underlying distribution with a number of samples that scale linearly with the intrinsic dimension. This work offers a robust explanation for the empirical success of diffusion models and suggests a path forward for developing more efficient and scalable generative models in AI research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.

")


: An Adapter-First Playbook")





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment