



LLMs exhibit remarkable language abilities, prompting questions about their memory mechanisms. Unlike humans, who use memory for daily tasks, LLMs’ “memory” is derived from input rather than stored externally. Research efforts have aimed to improve LLMs’ retention by extending context length and incorporating external memory systems. However, these methods do not fully clarify how memory operates within these models. The occasional provision of outdated information by LLMs indicates a form of memory, though its precise nature is unclear. Understanding how LLM memory differs from human memory is essential for advancing AI research and its applications.
Hong Kong Polytechnic University researchers use the Universal Approximation Theorem (UAT) to explain memory in LLMs. They propose that LLM memory, termed “Schrödinger’s memory,” is only observable when queried, as its presence remains indeterminate otherwise. Using UAT, they argue that LLMs dynamically approximate past information based on input cues, resembling memory. Their study introduces a new method to assess LLM memory abilities and compares LLMs’ memory and reasoning capacities to those of humans, highlighting both similarities and differences. The study also provides theoretical and experimental evidence supporting LLMs’ memory capabilities.
The UAT forms the basis of deep learning and explains memory in Transformer-based LLMs. UAT shows that neural networks can approximate any continuous function. In Transformer models, this principle is applied dynamically based on input data. Transformer layers adjust their parameters as they process information, allowing the model to fit functions in response to different inputs. Specifically, the multi-head attention mechanism modifies parameters to handle and retain information effectively. This dynamic adjustment enables LLMs to exhibit memory-like capabilities, allowing them to recall and utilize past details when responding to queries.
The study explores the memory capabilities of LLMs. First, it defines memory as requiring both input and output: memory is triggered by input, and the output can be correct, incorrect, or forgotten. LLMs exhibit memory by fitting input to a corresponding output, much like human recall. Experiments using Chinese and English poem datasets tested models’ ability to recite poems based on minimal input. Results showed that larger models with better language understanding performed significantly better. Additionally, longer input text reduced memory accuracy, indicating a correlation between input length and memory performance.
The study argues that LLMs possess memory and reasoning abilities similar to human cognition. Like humans, LLMs dynamically generate outputs based on learned knowledge rather than storing fixed information. The researchers suggest that human brains and LLMs function as dynamic models that adjust to inputs, fostering creativity and adaptability. Limitations in LLM reasoning are attributed to model size, data quality, and architecture. The brain’s dynamic fitting mechanism, exemplified by cases like Henry Molaison’s, allows for continuous learning, creativity, and innovation, paralleling LLMs’ potential for complex reasoning.
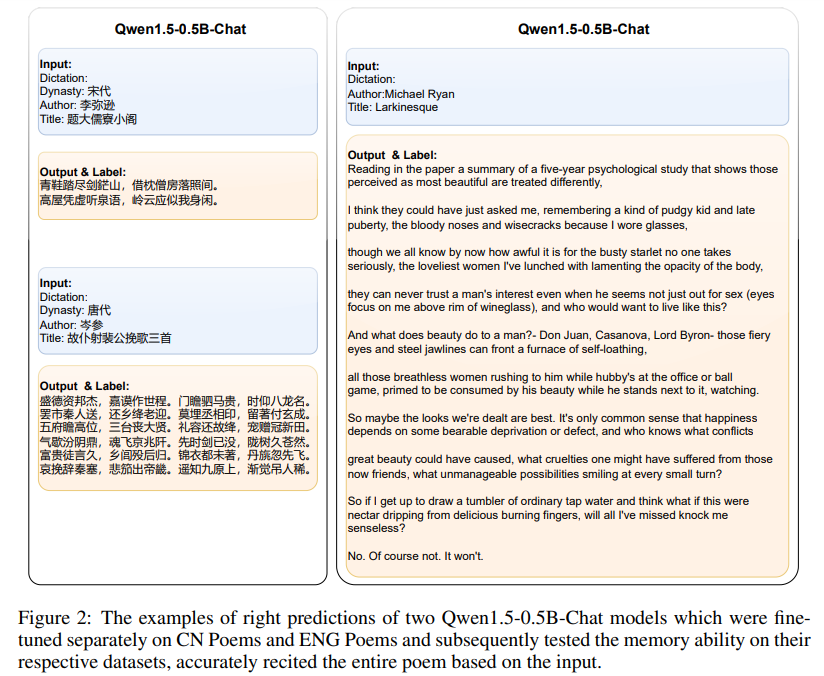
In conclusion, the study demonstrates that LLMs, supported by their Transformer-based architecture, exhibit memory capabilities similar to human cognition. LLM memory, termed “Schrödinger’s memory,” is revealed only when specific inputs trigger it, reflecting the UAT in its dynamic adaptability. The research validates LLM memory through experiments and compares it with human brain function, finding parallels in their dynamic response mechanisms. The study suggests that LLMs’ memory operates like human memory, becoming apparent only through specific queries, and explores the similarities and differences between human and LLM cognitive processes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment