



Test-time aggregation strategies, such as generating and combining multiple answers, can enhance LLM performance but eventually hit diminishing returns. Refinement, where model feedback is used to improve answers iteratively, presents an alternative. However, it faces three challenges: (1) excessive refinement, which can lead to over-correction and reduced accuracy; (2) difficulty in identifying and addressing specific errors, as LLMs struggle with targeted self-correction; and (3) determining the right amount of refinement, as insufficient refinement can leave errors unresolved while excessive iterations waste computational resources.
Researchers at UNC-Chapel Hill introduced MAGICORE, a framework for Multi-Agent Iteration for Coarse-to-Fine Refinement. MAGICORE addresses excessive refinement by classifying problems as easy or hard, solving easy ones with coarse aggregation and hard ones with fine, iterative multi-agent refinement. The system uses three agents—Solver, Reviewer, and Refiner—enhanced by step-wise Reward Model (RM) scores for error localization and feedback. MAGICORE outperforms methods like Self-Refine and Best-of-k across multiple math reasoning datasets, with significant performance gains even after one iteration. It continues to improve with more iterations, highlighting its efficiency and refinement capabilities.
MAGICORE improves reasoning through multi-agent collaboration and coarse-to-fine refinement. While Self-Consistency (SC) generates multiple solutions and selects the most frequent answer, MAGICORE uses external RMs to guide refinement, avoiding SC’s limitations. Unlike past methods that rely on LLM self-verification, MAGICORE uses RMs to identify errors and refine responses effectively. It employs a multi-agent system, where agents take distinct roles—solver, reviewer, and refiner—to improve solutions iteratively. This approach avoids excessive or insufficient refinement and enhances performance across various tasks, outperforming aggregation methods and LLM-based self-evaluation techniques.
MAGICORE is an adaptive framework designed to enhance the performance and efficiency of multi-step reasoning in LLMs by using intelligent test-time aggregation and refinement. It categorizes problems as easy or hard, applying coarse aggregation for simpler tasks and fine-grained, iterative multi-agent refinement for more complex ones. The framework utilizes two reward models: an Outcome Reward Model (ORM) for overall solution quality and a Process Reward Model (PRM) for step-by-step accuracy. MAGICORE employs three agents—the Solver, Reviewer, and Refiner—to generate, evaluate, and improve solutions iteratively until optimal answers are achieved. This approach prevents excessive refinement, improves error localization, and ensures thorough solution enhancement.
MAGICORE surpasses all baseline methods after just one iteration, demonstrating a 3.2% improvement over Best-of-120 on Llama-3-8B while using half the samples. Compared to Self-Refine and Self-Refine with Self-Consistency, MAGICORE shows significant gains of up to 17.1% on Llama-3-8B and 5.4% over combined baselines. MAGICORE continues to enhance the accuracy as iterations increase, stabilizing at 75.6%, unlike fluctuating baselines. Additionally, MAGICORE efficiently uses fewer samples, avoids over-correction through selective refinement, and benefits from its multi-agent setup. Separate roles for Reviewer and Refiner further improve performance, highlighting MAGICORE’s effective adaptive refinement strategy.
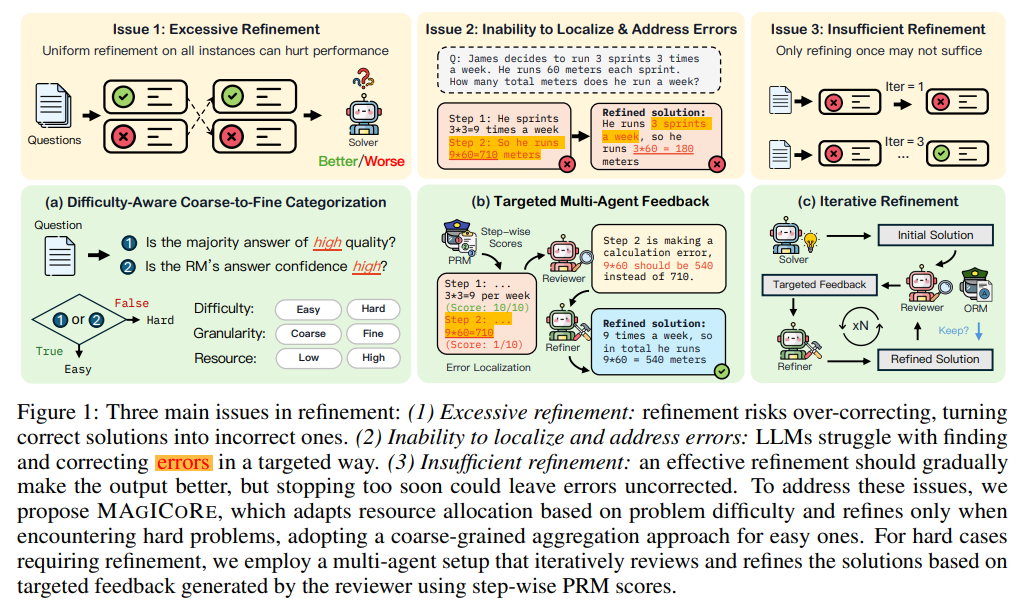
MAGICORE adaptively allocates computational resources to challenging problems, using selective refinement for harder cases. It addresses excessive refinement, LLMs’ limitations in error detection, and insufficient refinement. By combining global and local reward models, MAGICORE determines which problems need refinement and uses iterative feedback to improve accuracy. Tested on math datasets and two models, MAGICORE consistently outperforms baseline methods, even those with higher computational demands. Unlike traditional strategies that stagnate, MAGICORE’s performance improves with additional iterations, highlighting the importance of selective refinement and multi-agent communication in enhancing problem-solving capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
: A Diffusion Model for Efficient Video Generation with Motion Reuse")









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment