



Large language models (LLMs) have transformed fields ranging from customer service to medical assistance by aligning machine output with human values. Reward models (RMs) play an important role in this alignment, essentially serving as a feedback loop where models are guided to provide human-preferred responses. While many advancements have optimized these models for English, a broader challenge exists in adapting RMs to multilingual contexts. This adaptation is essential, given the global user base that increasingly relies on LLMs across diverse languages for various tasks, including everyday information, safety guidelines, and nuanced conversations.
A core issue in LLM development lies in adapting RMs to perform consistently across different languages. Traditional reward models, primarily trained on English-language data, often must catch up when extended to other languages. This limitation creates a performance gap that restricts these models’ applicability, particularly for non-English users who depend on language models for accurate, culturally relevant, and safe responses. The current gap in RM capabilities underscores the need for multilingual benchmarks and evaluation tools to ensure models serve a global audience more effectively.
Existing evaluation tools, such as RewardBench, focus on assessing models in English for general capabilities like reasoning, chat functionality, and user safety. While this benchmark has established a baseline for evaluating English-based RMs, it must address the multilingual dimensions necessary for broader applicability. RewardBench, as it stands, does not fully account for tasks involving translation or cross-cultural responses. This highlights a critical area for improvement, as accurate translations and culturally aligned responses are foundational for a meaningful user experience across different languages.
Researchers from Writesonic, Allen Institute for AI, Bangladesh University of Engineering and Technology, ServiceNow, Cohere For AI Community, Cohere, and Cohere For AI developed the M-RewardBench, a new multilingual evaluation benchmark designed to test RMs across a spectrum of 23 languages. The dataset, spanning 2,870 preference instances, includes languages from eight unique scripts and multiple language families, providing a rigorous multilingual test environment. M-RewardBench aims to bridge the RM evaluation gap by covering languages from varied typological backgrounds, bringing new insights into how LLMs perform across non-English languages in essential areas such as safety, reasoning, chat capability, and translation.
M-RewardBench methodology comprehensively evaluates multilingual reward models, employing both machine-generated and human-verified translations for accuracy. The researchers crafted subsets based on task difficulty and language complexity, translating and adapting RewardBench prompts across 23 languages. The benchmark includes Chat, Chat-Hard, Safety, and Reasoning categories to assess RM’s capabilities in everyday and complex conversational settings. To measure the impact of translation quality, the research team used two translation systems, Google Translate and NLLB 3.3B, demonstrating that improved translation can significantly enhance RM performance by up to 3%.
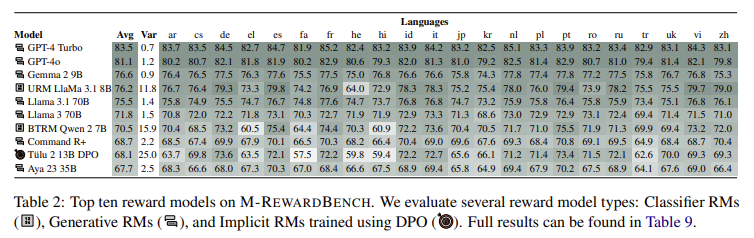
The study revealed substantial performance disparities, particularly between English and non-English contexts. Generative reward models, such as GPT-4-Turbo, performed relatively well, achieving an 83.5% accuracy score, while other RM types, such as classifier-based models, struggled with the shift to multilingual tasks. The results indicate that generative models are better suited for multilingual alignment, although an average performance drop of 8% when transitioning from English to non-English tasks remains. Also, the performance of models varied significantly by language, with high-resource languages like Portuguese achieving a higher accuracy (68.7%) compared to lower-resource languages like Arabic (62.8%).
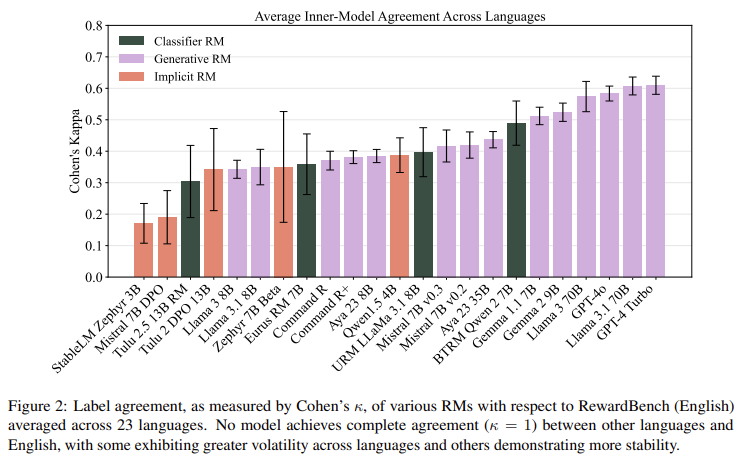
Several key insights emerged from M-RewardBench, underscoring areas for improvement in multilingual RM development. For example, RMs showed a higher degree of label consistency across languages for reasoning tasks than for general chat conversations, suggesting that certain types of content may be more adaptable to multilingual contexts. This insight points to a need for specialized benchmarks within M-RewardBench to evaluate different types of content, especially as models expand into underrepresented languages with unique grammatical structures.
Key Takeaways from the research:
- Dataset Scope: M-RewardBench spans 23 languages, eight language families, and 2,870 preference instances, making it one of the most comprehensive multilingual RM evaluation tools available.
- Performance Gaps: Generative RMs achieved higher average scores, with a significant 83.5% in multilingual settings, but overall performance dropped by up to 13% for non-English tasks.
- Task-Specific Variations: Chat-Hard tasks showed the greatest performance degradation (5.96%), while reasoning tasks had the least, highlighting that task complexity impacts RM accuracy across languages.
- Translation Quality Impact: Higher-quality translations improved RM accuracy by up to 3%, emphasizing the need for refined translation methods in multilingual contexts.
- Consistency in High-Resource Languages: Models performed better in high-resource languages (e.g., Portuguese, 68.7%) and showed consistency issues in lower-resource languages, such as Arabic (62.8%).
- Benchmark Contribution: M-RewardBench provides a new framework for assessing LLMs in non-English languages, setting a foundation for future improvements in RM alignment across cultural and linguistic contexts.

In conclusion, the research behind M-RewardBench illustrates a critical need for language models to align more closely with human preferences across languages. By providing a benchmark tailored for multilingual contexts, this research lays the groundwork for future improvements in reward modeling, especially in handling cultural nuances and ensuring language consistency. The findings reinforce the importance of developing RMs that reliably serve a global user base, where language diversity and translation quality are central to performance.
Check out the Paper, Project, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment