



Using large language models (LLMs) has revolutionized artificial intelligence applications, enabling breakthroughs in natural language processing tasks like conversational AI, content generation, and automated code completion. Often with billions of parameters, these models rely on massive memory resources to store intermediate computation states and large key-value caches during inference. These models’ computational intensity and growing size demand innovative solutions to manage memory without sacrificing performance.
A critical challenge with LLMs is the limited memory capacity of GPUs. When GPU memory becomes insufficient to store the required data, systems offload portions of the workload to CPU memory, a process known as swapping. While this expands memory capacity, it introduces delays due to data transfer between CPU & GPU, significantly impacting the throughput and latency of LLM inference. The trade-off between increasing memory capacity and maintaining computation efficiency remains a key bottleneck in advancing LLM deployment at scale.
Current solutions like vLLM and FlexGen attempt to address this issue through various swapping techniques. vLLM employs a paged memory structure to manage the key-value cache, improving memory efficiency to some extent. FlexGen, on the other hand, uses offline profiling to optimize memory allocation across GPU, CPU, and disk resources. However, these approaches often need more predictable latency, delayed computations, and an inability to dynamically adapt to workload changes, leaving room for further innovation in memory management.

Researchers from UC Berkeley introduced Pie, a novel inference framework designed to overcome the challenges of memory constraints in LLMs. Pie employs two core techniques: performance-transparent swapping and adaptive expansion. Leveraging predictable memory access patterns and advanced hardware features like NVIDIA GH200 Grace Hopper Superchip’s high-bandwidth NVLink, Pie dynamically extends memory capacity without adding computational delays. This innovative approach allows the system to mask data transfer latencies by executing them concurrently with GPU computations, ensuring optimal performance.
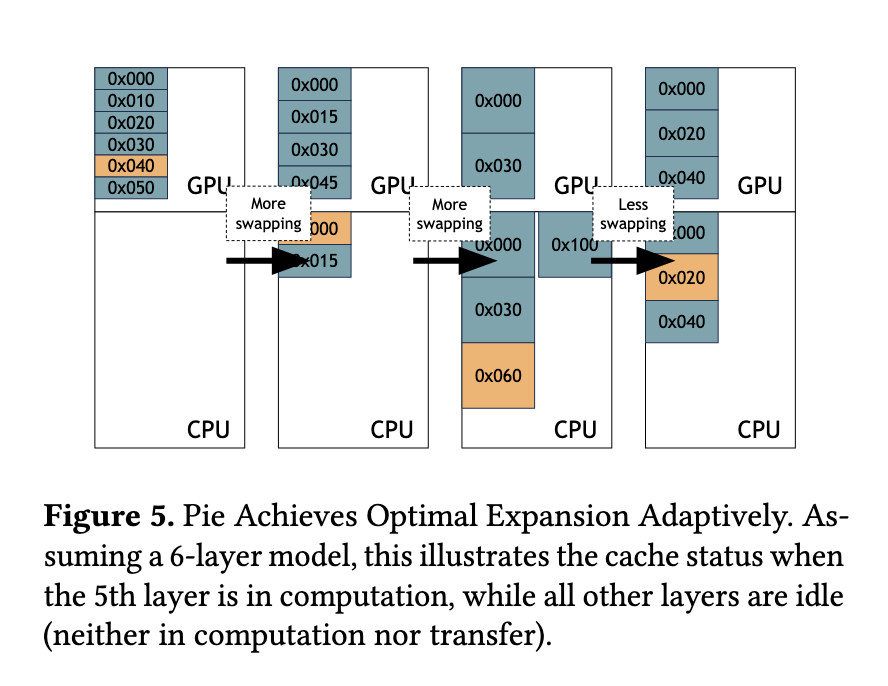
Pie’s methodology revolves around two pivotal components. Performance-transparent swapping ensures that memory transfers do not delay GPU computations. This is achieved by prefetching data into the GPU memory in anticipation of its use, utilizing the high bandwidth of modern GPUs and CPUs. Meanwhile, adaptive expansion adjusts the amount of CPU memory used for swapping based on real-time system conditions. By dynamically allocating memory as needed, Pie prevents under-utilization or excessive swapping that could degrade performance. This design allows Pie to seamlessly integrate CPU and GPU memory, effectively treating the combined resources as a single, expanded memory pool for LLM inference.
Pie’s experimental evaluations demonstrated remarkable improvements in performance metrics. Compared to vLLM, Pie achieved up to 1.9× higher throughput and 2× lower latency in various benchmarks. Further, Pie reduced GPU memory usage by 1.67× while maintaining comparable performance. Against FlexGen, Pie showed an even greater advantage, achieving up to 9.4× higher throughput and significantly reduced latency, particularly in scenarios involving larger prompts and more complex inference workloads. The experiments utilized state-of-the-art models, including OPT-13B and OPT-30B, and ran on NVIDIA Grace Hopper instances with up to 96GB of HBM3 memory. The system efficiently handled real-world workloads from datasets like ShareGPT and Alpaca, proving its practical viability.
Pie’s ability to dynamically adapt to varying workloads and system environments sets it apart from existing methods. The adaptive expansion mechanism quickly identifies the optimal memory allocation configuration during runtime, ensuring minimal latency and maximum throughput. Even under constrained memory conditions, Pie’s performance-transparent swapping enables efficient utilization of resources, preventing bottlenecks and maintaining high system responsiveness. This adaptability was particularly evident during high-load scenarios, where Pie scaled effectively to meet demand without compromising performance.

Pie represents a significant advancement in AI infrastructure by addressing the longstanding challenge of memory limitations in LLM inference. Its ability to seamlessly expand GPU memory with minimal latency paves the way for deploying larger and more complex language models on existing hardware. This innovation enhances the scalability of LLM applications and reduces the cost barriers associated with upgrading hardware to meet the demands of modern AI workloads. As LLMs grow in scale and application, frameworks like Pie will enable efficient and widespread use.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
Why AI-Language Models Are Still Vulnerable: Key Insights from Kili Technology’s Report on Large Language Model Vulnerabilities [Read the full technical report here]
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment