



Natural Language Processing (NLP) has advanced significantly with deep learning, driven by innovations like word embeddings and transformer architectures. Self-supervised learning uses vast amounts of unlabeled data to create pretraining tasks and has become a key approach for training models, especially in high-resource languages like English and Chinese. The disparity in NLP resources and performance ranges from high-resource language systems, such as English and Chinese, to low-resource language systems, such as Portuguese, and more than 7000 languages worldwide. Such a gap hinders the ability of NLP applications of low-resource languages to grow and be more robust and accessible. Also, low-resource monolingual models remain small-scale and undocumented, and they lack standard benchmarks, which makes development and evaluation difficult.

Current development methods often utilize vast amounts of data and computational resources readily available for high-resource languages like English and Chinese. Portuguese NLP mostly uses multilingual models like mBERT, mT5, and BLOOM or fine-tunes English-trained models. However, these methods often miss the unique aspects of Portuguese. The evaluation benchmarks are either old or based on English datasets, making them less useful for Portuguese.
To address this, researchers from the University of Bonn have developed GigaVerbo, a large-scale Portuguese text corpus of 200 billion tokens, and trained a series of decoder-transformers named Tucano. These models aim to improve the performance of Portuguese language models by leveraging a substantial and high-quality dataset.
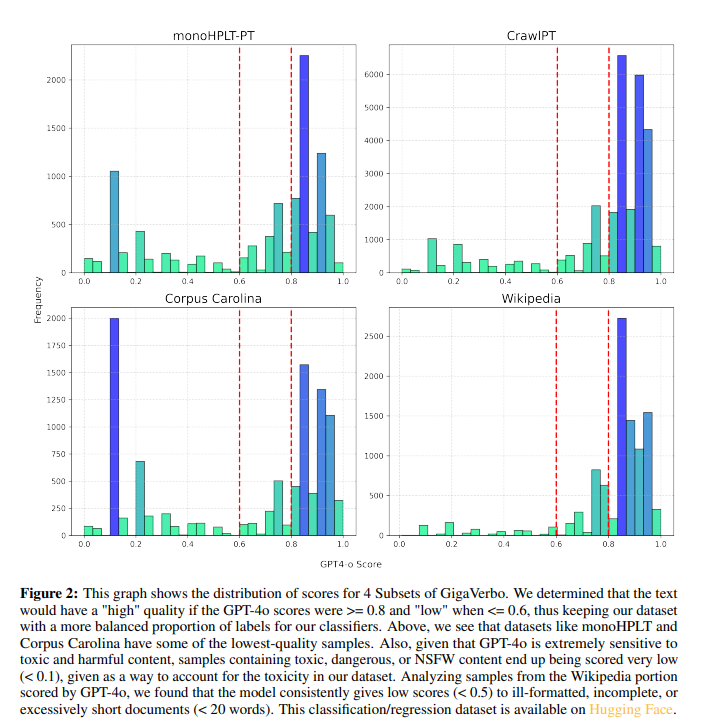
The GigaVerbo dataset is a concatenation of multiple high-quality Portuguese text corpora, refined using custom filtering techniques based on GPT-4 evaluations. The filtering process improved text preprocessing, retaining 70% of the dataset for the model. Based on the Llama architecture, the Tucano models were implemented using Hugging Face for easy community access. Techniques such as RoPE embeddings, root mean square normalization, and Silu activations instead of SwiGLU were used. The training was done using a causal language modeling approach and cross-entropy loss. The models range from 160M to 2.4B parameters, with the largest trained on 515 billion tokens.
The evaluation of these models shows that they perform equal to or better than other Portuguese and multilingual language models of similar size on several Portuguese benchmarks. The training loss and validation perplexity curves for the four base models showed that larger models generally reduced loss and perplexity more effectively, with the effect amplified by larger batch sizes. Checkpoints were saved every 10.5 billion tokens, and performance was tracked across several benchmarks. Pearson correlation coefficients indicated mixed results: some benchmarks, like CALAME-PT, LAMBADA, and HellaSwag, improved with scaling, while others, such as the OAB Exams, showed no correlation with token ingestion. Inverse scaling was observed in sub-billion parameter models, suggesting potential limitations. Performance benchmarks also reveal that Tucano outperforms multilingual and prior Portuguese models on native evaluations like CALAME-PT and machine-translated tests like LAMBADA.
In conclusion, the GigaVerbo and the Tucano series enhance the performance of Portuguese language models. The proposed work covered the development pipeline, which included dataset creation, filtration, hyperparameter tuning, and evaluation, with a focus on openness and reproducibility. It also showed the potential for improving low-resource language models through large-scale data collection and advanced training techniques. The contribution of these researchers will prove beneficial in providing these necessary resources to guide future studies.
Check out the Paper and Hugging Face Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science degree at the Indian Institute of Technology (IIT) Kharagpur. She has a deep passion for Data Science and actively explores the wide-ranging applications of artificial intelligence across various industries. Fascinated by technological advancements, Nazmi is committed to understanding and implementing cutting-edge innovations in real-world contexts.









 Servers Worth Exploring")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment