



Multimodal large language models (MLLMs) have emerged as a promising approach towards artificial general intelligence, integrating diverse sensing signals into a unified framework. However, MLLMs face substantial challenges in fundamental vision-related tasks, significantly underperforming compared to human capabilities. Critical limitations persist in object recognition, localization, and motion recall, presenting obstacles to comprehensive visual understanding. Despite ongoing research and scaling efforts, a clear pathway to achieving human-level visual comprehension remains elusive. The current work highlights the complexity of developing adaptive and intelligent multimodal systems that can interpret and reason across different sensory inputs with human-like precision and flexibility.
Existing research on MLLMs has pursued multiple approaches to address visual understanding challenges. Current methodologies combine vision encoders, language models, and connectors through instruction tuning, enabling complex tasks like image description and visual query responses. Researchers have explored various dimensions including model architecture, model size, training corpus, and performance optimization. Video-capable MLLMs have shown capabilities in processing sequential visuals and comprehending spatiotemporal variations. However, existing methods face significant limitations in handling fine-grained visual tasks such as precise segmentation and temporal grounding, so two strategies have emerged to tackle these challenges: the pixel-to-sequence (P2S) methodology, and the pixel-to-embedding (P2E) approach.
Researchers from Shanghai AI Laboratory, Nanjing University, and Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences have proposed a new version of InternVideo2.5, a novel approach to improve video MLLM through long and rich context (LRC) modeling. It addresses limitations in perceiving fine-grained video details and capturing complex temporal structures. The proposed method focuses on integrating dense vision task annotations into MLLMs using direct preference optimization and developing compact spatiotemporal representations through adaptive hierarchical token compression. The researchers aim to expand the model’s capabilities in video understanding, enabling more robust performance across various benchmarks.
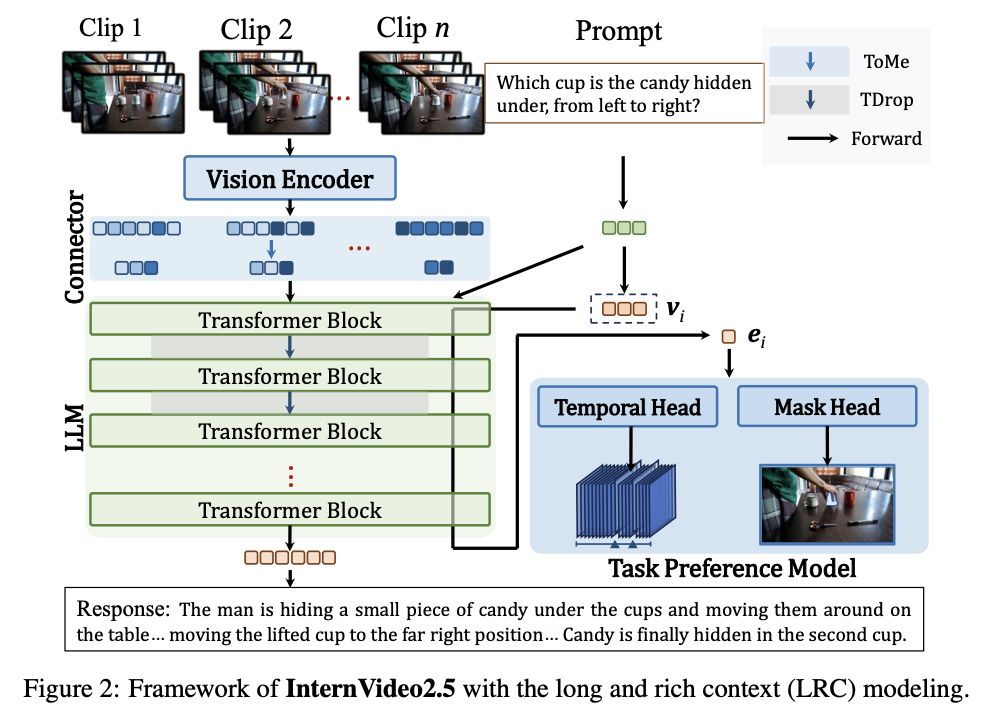
The proposed architecture presents a complex multimodal framework that integrates advanced video processing and language modeling techniques. The system uses dynamic video sampling, processing between 64 to 512 frames, with each 8-frame clip compressed to 128 tokens, resulting in 16 tokens per frame representation. Key architectural components include a Temporal Head based on CG-DETR architecture and a Mask Head utilizing SAM2’s pre-trained weights. For temporal processing, the framework utilizes InternVideo2 for video feature extraction, with query features processed through the language model. The system implements two-layer MLPs for positioning prompts and spatial input encoding into the multimodal language model to optimize spatiotemporal capabilities.
InternVideo2.5 demonstrates remarkable performance across video understanding benchmarks in short and long video question-answering tasks. Compared to its base model InternVL2.5, the proposed approach shows significant improvements, with notable increases of over 3 points on MVBench and Perception Test for short video predictions. InternVideo2.5 exhibits superior performance in short-duration spatiotemporal understanding, compared to models like GPT4-o and Gemini-1.5-Pro. The Needle-In-The-Haystack (NIAH) evaluation further validates the model’s enhanced implicit memory capabilities, successfully showing superior recall in a complex 5,000-frame single-hop task.
In conclusion, researchers introduced a new version of InternVideo2.5, a novel video MLLM designed to enhance perception and understanding through long and rich context (LRC) modeling. The method utilizes direct preference optimization to transfer dense visual annotations and adaptive hierarchical token compression for efficient spatiotemporal representation. The research highlights significant improvements in visual capabilities, including object tracking, and underscores the critical importance of multimodal context resolution in advancing MLLM performance. However, the study shows limitations such as high computational costs and the need for further research in extending context processing techniques, presenting exciting opportunities for future investigation in the multimodal AI field.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
")
")





: A Human-Inspired Diffusion Framework for Advanced Deep Research Agents")


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment