



Reasoning language models have demonstrated the ability to enhance performance by generating longer chain-of-thought sequences during inference, effectively leveraging increased computation. However, a major limitation is the lack of control over reasoning length, making it difficult to allocate computational resources efficiently. In some cases, models generate excessively long outputs, wasting compute, while in others, they stop too soon, leading to suboptimal performance. Existing approaches often degrade performance, such as enforcing special tokens like “Wait” or “Final Answer” to regulate output length. Unlike general text generation, reasoning tasks require a balance between computational efficiency and accuracy, highlighting the need for precise length control.
Prior research has explored test-time scaling strategies, demonstrating that increasing inference computation—through longer reasoning chains or parallel sampling—improves performance in complex reasoning tasks like mathematical problem-solving and code generation. However, current methods lack fine-grained control over reasoning length, leading to inefficiencies. While previous work on output length control has primarily focused on instruction-following models or general text generation, reasoning models pose unique challenges due to their need for dynamic adjustment of inference length. Recent attempts, such as budget-enforced truncation, disrupt reasoning coherence and hinder accuracy. Addressing these gaps, this research introduces a method for explicitly controlling reasoning length, optimizing computational cost while maintaining performance.
Researchers at Carnegie Mellon University introduce Length Controlled Policy Optimization (LCPO), a reinforcement learning approach that enhances reasoning models by ensuring accuracy and adherence to user-specified length constraints. LCPO-trained models, such as L1, efficiently balance computational cost and performance by adjusting reasoning length through prompt-based constraints. L1 surpasses the S1 method and even outperforms GPT-4o at equivalent reasoning lengths. Additionally, LCPO improves model generalization to logical reasoning and knowledge benchmarks like MMLU. Notably, models trained with LCPO exhibit strong short chain-of-thought capabilities, achieving high accuracy while maintaining precise length control across various tasks.
Traditional reasoning models lack mechanisms for controlling output length, making it difficult to manage computational budgets. LCPO addresses this by conditioning the model on a target length given in the prompt. The model is trained using RL with a reward function balancing accuracy and adherence to length constraints. This results in two variants: L1-Exact, which strictly matches the target length, and L1-Max, which stays within a specified maximum length. L1-Max allows flexibility while prioritizing correctness. This method enhances efficiency by optimizing reasoning performance while ensuring computational cost remains manageable.
The proposed LCPO method (L1) demonstrates superior performance in length-controlled text generation across various benchmarks. L1-Exact and L1-Max consistently outperform baseline models while maintaining precise token constraints. Compared to S1, L1 achieves 20-25% absolute and over 100% relative gains by effectively adapting reasoning chains without truncation. L1 generalizes well to out-of-domain tasks, exhibiting robust performance scaling. It maintains high precision in length adherence, with minimal deviation in mathematical reasoning tasks. Additionally, L1 employs adaptive reasoning strategies, allocating more tokens for self-correction and conclusions at longer lengths while preserving an efficient balance between intermediate reasoning steps and final outputs.
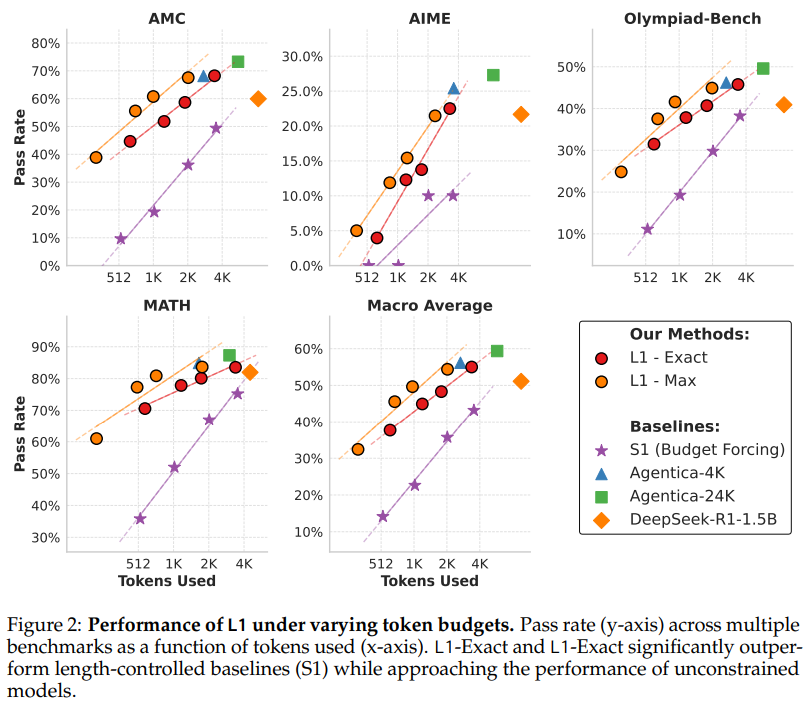
In conclusion, the study presents LCPO, a reinforcement learning method that enables precise control over the length of reasoning chains in language models. Using LCPO, we train L1, a reasoning model that adheres to user-specified length constraints while optimizing accuracy. L1 surpasses previous length-control approaches, achieving over 100% relative and 20% absolute improvements in mathematical reasoning. It generalizes well to out-of-domain tasks and unexpectedly excels in short chain-of-thought reasoning, outperforming larger models like GPT-4o at equal lengths. LCPO offers a scalable and efficient approach to balancing computational cost and accuracy through simple prompt-based length control.
Check out the Paper, Model on Hugging Face, and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.





 Framework that Enables Partially Unmasked Tokens during Sampling")




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment