



Cohere For AI has just dropped a bombshell: Aya Vision, a open-weights vision model that’s about to redefine multilingual and multimodal communication. Prepare for a seismic shift as we shatter language barriers and unlock the true potential of AI across the globe!
Smashing the Multilingual Multimodal Divide!
Let’s face it, AI has been speaking with a frustratingly limited vocabulary. But not anymore! Aya Vision explodes onto the scene, obliterating the performance gap between languages and modalities. This isn’t just an incremental improvement; it’s a quantum leap, extending multimodal magic to 23 languages, reaching over half the planet’s population. Imagine AI finally speaking your language, understanding the rich tapestry of your culture.
Aya Vision: Where Vision Meets Linguistic Brilliance!
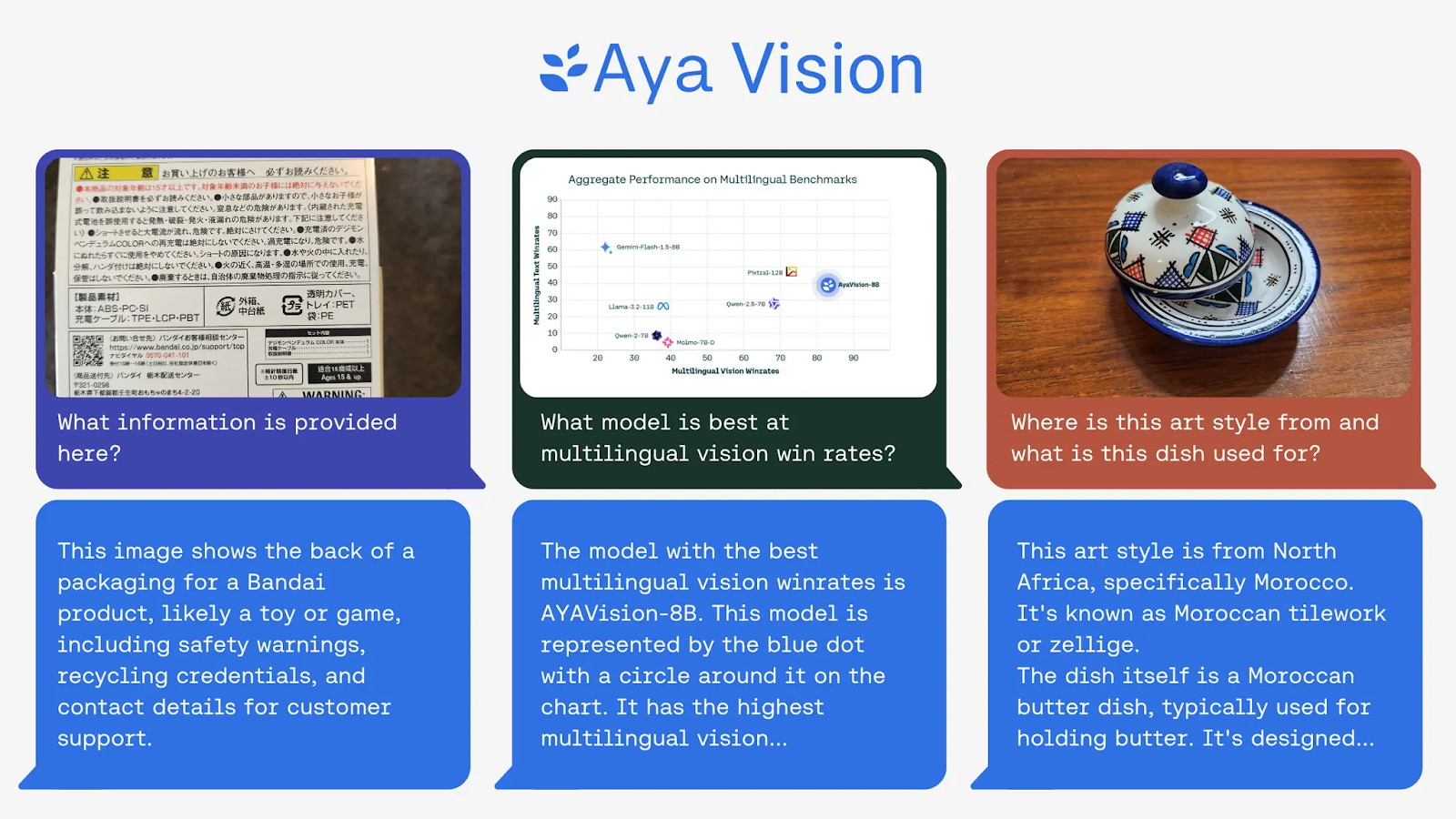
This is not your average vision model. Aya Vision is a linguistic virtuoso, a visual maestro, and a global communicator all rolled into one. From crafting captivating image captions to answering complex visual questions, it’s a powerhouse of multimodal understanding. See above: you snap a photo of a stunning piece of art from your travels, and Aya Vision instantly unveils its history, style, and cultural significance, bridging worlds with a single image.
Performance That Will Blow Your Mind!
- Multilingual Domination: Aya Vision obliterates the competition, leaving leading open-weights models in the dust when it comes to multilingual text generation and image understanding.
- Parameter Prowess: The 8B model is a lean, mean, performance machine, crushing giants like Qwen2.5-VL 7B, Gemini Flash 1.5 8B, Llama-3.2 11B Vision, and Pangea 7B with jaw-dropping win rates!
- 32B Titan: The 32B model sets a new gold standard, outperforming even larger models like Llama-3.2 90B Vision, Molmo 72B, and Qwen2-VL 72B with breathtaking efficiency.
- Efficiency Unleashed: Aya Vision proves you don’t need monstrous models to achieve monumental results, outperforming models 10x its size!
- Algorithmic Alchemy: Secret ingredients like synthetic annotations, multilingual data scaling, and multimodal model merging have been masterfully combined to create this AI masterpiece.

Open Weights, Open Doors, Open World!
Cohere For AI isn’t just building groundbreaking AI; they’re democratizing it. Aya Vision’s 8B and 32B models are now freely available on Kaggle and Hugging Face.
Want to contribute?
Cohere For AI invites researchers worldwide to join the Aya initiative, apply for research grants, and collaborate in their open science community. Aya Vision is a huge step forward into the future of multilingual multimodal.
Check out Aya Vision blog post and Aya Initiative, Kaggle and Hugging Face. . All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

Jean-marc is a successful AI business executive .He leads and accelerates growth for AI powered solutions and started a computer vision company in 2006. He is a recognized speaker at AI conferences and has an MBA from Stanford.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment