


: A Multi-Agent Approach to Accountability in Conversational Medical AI")
Recent advances in large language model (LLM)-powered diagnostic AI agents have yielded systems capable of high-quality clinical dialogue, differential diagnosis, and management planning in simulated settings. Yet, delivering individual diagnoses and treatment recommendations remains strictly regulated: only licensed clinicians can be responsible for critical patient-facing decisions. Traditional healthcare often employs hierarchical oversight—an experienced physician reviews and authorizes diagnostic and management plans proposed by advanced practice providers (APPs) such as nurse practitioners (NPs) and physician assistants (PAs). As such, medical AI deployment demands oversight paradigms that mirror these safety protocols.
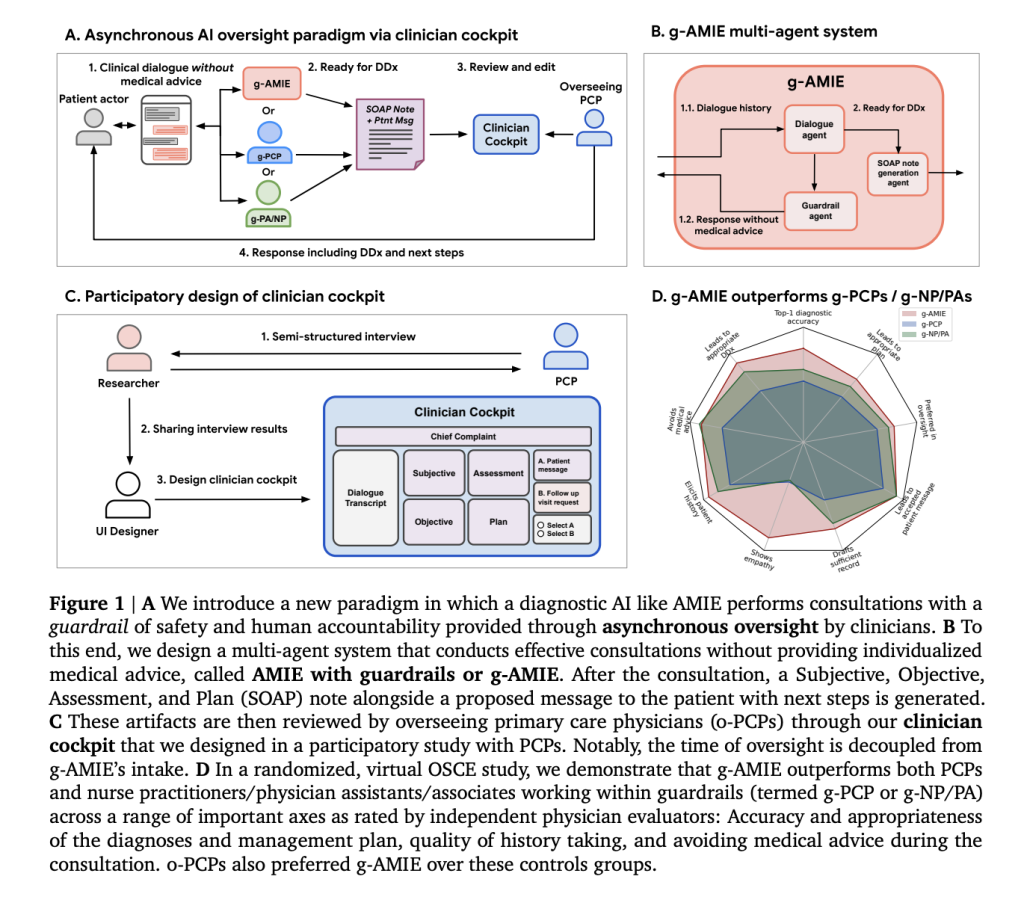
System Design: Guardrailed Diagnostic AI with Asynchronous Oversight
A team of researchers from Google DeepMind, Google Research, and Harvard Medical School proposed a multi-agent architecture called guardrailed-AMIE (g-AMIE), built atop Gemini 2.0 Flash and based on the Articulate Medical Intelligence Explorer (AMIE). This system strictly separates patient history intake from delivery of individualized medical advice:
- Intake with Guardrails: The AI conducts history-taking dialogues, documents symptoms, and summarizes clinical context without providing any diagnosis or management recommendation directly to the patient. A dedicated “guardrail agent” monitors each response to ensure compliance, filtering potential medical advice before communication.
- SOAP Note Generation: Once intake concludes, a separate agent synthesizes a structured clinical summary in SOAP format (Subjective, Objective, Assessment, Plan), incorporating chain-of-thought reasoning and constrained decoding for accuracy and consistency.
- Clinician Cockpit: Licensed physicians (overseeing PCPs) review, edit, and authorize the AI-generated SOAP note and patient-facing message through an interactive cockpit interface, designed through participatory interviews with clinicians. Physicians can make detailed edits, provide feedback, and decide whether to proceed with the AI’s recommendation or request a follow-up.
This workflow decouples intake from oversight, allowing asynchronous physician review—significantly increasing scalability compared to “live” supervision required in some prior telehealth implementations.
Evaluation: Rigorous OSCE Study and Auto-Rater Validation
To validate the paradigm, the research team conducted a randomized, blinded virtual Objective Structured Clinical Examination (OSCE). Key components included:
- Comparison Groups: g-AMIE was evaluated against control groups—early-career PCPs (g-PCPs) and a mixed group of NPs/PAs (g-NP/PA)—all operating under identical guardrails, with oversight by senior PCPs (o-PCPs).
- Scenario Packs: 60 hand-crafted clinical scenarios were used, selected with difficulty calibrated against UK guidance for physician assistants. Patient actors simulated cases, interacting with the AI or human clinicians.
- Rubrics and Metrics: Composite quality of dialogue, SOAP note completeness/readability/accuracy (modified QNote rubric), diagnostic and management plan correctness, and oversight experience were measured by independent physicians, patient actors, and automated LLM-based “auto-raters”.
Key Results and Findings
- Guardrail Adherence and Intake Quality: g-AMIE and g-NP/PAs successfully abstained from giving medical advice in >90% of scenarios, compared to 71.7% for g-PCPs. Intake by g-AMIE covered more critical “red flag” symptoms (64.2%) than control groups.
- SOAP Note Quality: g-AMIE’s initial, unedited SOAP notes consistently outperformed those from control groups in readability, completeness, and accuracy, as rated by clinicians and auto-raters.
- Efficiency: Oversight time for g-AMIE cases was about 40% less than full PCP consultations, demonstrating substantial workflow efficiency gains for physicians.
- Diagnostic and Management Plan Accuracy: Using auto-raters and independent physician assessment, g-AMIE achieved 81.7% top-1 diagnostic accuracy (vs. 53.3% g-PCP, 63.3% g-NP/PA), and higher management plan coverage.
- Oversight Experience and Decision Quality: o-PCPs reported better experience with g-AMIE and preferred its cases for oversight. Most edits involved improving conciseness, correcting confabulations, or adding critical escalations. Edits improved diagnostic quality for human control groups, but not consistently for g-AMIE.
- Patient Actor Preference: Across empathy, communication, and trust axes (PACES, GMC rubrics), simulated patients consistently preferred dialogues with g-AMIE.2507.
- Nurse Practitioners/PAs Outperform PCPs in Some Tasks: g-NP/PAs more successfully adhered to guardrails and elicited higher quality histories and differential diagnoses than g-PCP counterparts, possibly due to greater familiarity with protocolized intake.

Conclusion: Towards Responsible and Scalable Diagnostic AI
This work demonstrates that asynchronous oversight by licensed physicians—enabled by structured multi-agent diagnostic AI and dedicated cockpit tools—can enhance both efficiency and safety in text-based diagnostic consultations. Systems like g-AMIE outperform early-career clinicians and advanced practice providers in guarded intake, documentation quality, and composite decision-making under expert review. While real-world deployment demands further clinical validation and robust training, the paradigm represents a significant step forward in scalable human-AI medical collaboration, preserving accountability while realizing major efficiency gains.
Check out the FULL PAPER here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment