



Multimodal Large Language Models (MLLMs) have gained significant attention for their ability to handle complex tasks involving vision, language, and audio integration. However, they lack the comprehensive alignment beyond basic Supervised Fine-tuning (SFT). Current state-of-the-art models often bypass rigorous alignment stages, leaving crucial aspects like truthfulness, safety, and human preference alignment inadequately addressed. Existing approaches target only specific domains such as hallucination reduction or conversational improvements, falling short of enhancing the model’s overall performance and reliability. This narrow focus raises questions about whether human preference alignment can improve MLLMs across a broader spectrum of tasks.
Recent years have witnessed substantial progress in MLLMs, built upon advanced LLM architectures like GPTs, LLaMA, Alpaca, Vicuna, and Mistral. These models have evolved through end-to-end training approaches, tackling complex multimodal tasks involving image-text alignment, reasoning, and instruction following. Several open-source MLLMs, including Otter, mPLUG-Owl, LLaVA, Qwen-VL, and VITA, have emerged to address fundamental multimodal challenges. However, alignment efforts have remained limited. While algorithms like Fact-RLHF and LLAVACRITIC have shown promise in reducing hallucinations and improving conversational abilities, they haven’t enhanced general capabilities. Evaluation frameworks such as MME, MMBench, and Seed-Bench have been developed to assess these models.
Researchers from KuaiShou, CASIA, NJU, USTC, PKU, Alibaba, and Meta AI have proposed MM-RLHF, an innovative approach featuring a comprehensive dataset of 120k fine-grained, human-annotated preference comparison pairs. This dataset represents a significant advancement in terms of size, diversity, and annotation quality compared to existing resources. The method introduces two key innovations: a Critique-Based Reward Model that generates detailed critiques before scoring outputs, and Dynamic Reward Scaling that optimizes sample weights based on reward signals. It enhances both the interpretability of model decisions and the efficiency of the alignment process, addressing the limitations of traditional scalar reward mechanisms in multimodal contexts.
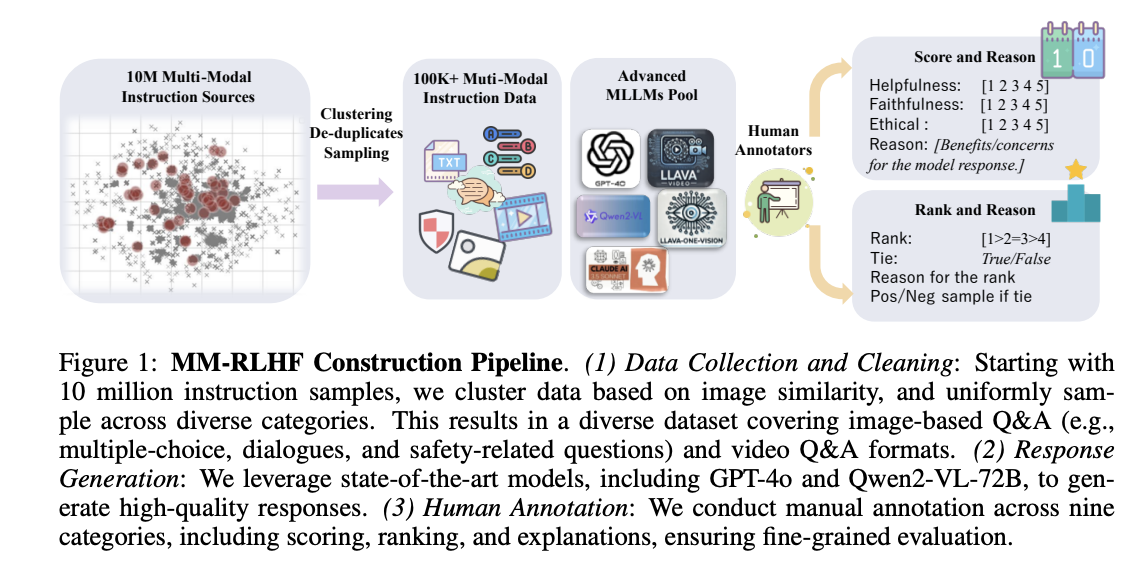
The MM-RLHF implementation involves a complex data preparation and filtering process across three main domains: image understanding, video understanding, and multimodal safety. The image understanding component integrates data from multiple sources including LLaVA-OV, VLfeedback, and LLaVA-RLHF, with multi-turn dialogues converted to single-turn format. This compilation results in over 10 million dialogue samples covering diverse tasks from basic conversation to complex reasoning. The data filtering process uses predefined sampling weights categorized into three types: multiple-choice questions for testing reasoning and perception, long-text questions for evaluating conversational abilities, and short-text questions for basic image analysis.
The evaluation of MM-RLHF and MM-DPO shows significant improvements across multiple dimensions when applied to models like LLaVA-OV-7B, LLaVA-OV-0.5B, and InternVL-1B. Conversational abilities improved by over 10%, while unsafe behaviors decreased by at least 50%. The aligned models show better results in hallucination reduction, mathematical reasoning, and multi-image understanding, even without specific training data for some tasks. However, model-specific variations are observed, with different models requiring distinct hyperparameter settings for optimal performance. Also, high-resolution tasks show limited gains due to dataset constraints and filtering strategies that don’t target resolution optimization.
In this paper, researchers introduced MM-RLHF, a dataset and alignment approach that shows significant advancement in MLLM development. Unlike previous task-specific approaches, this method takes a holistic approach to improve model performance across multiple dimensions. The dataset’s rich annotation granularity, including per-dimension scores and ranking rationales, offers untapped potential for future development. Future research directions will focus on utilizing this granularity through advanced optimization techniques, addressing high-resolution data limitations, and expanding the dataset through semi-automated methods, potentially establishing a foundation for more robust multimodal learning frameworks.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment