
 Training")


Vision Language Models (VLMs) allow both text inputs and visual understanding. However, image resolution is crucial for VLM performance for processing text and chart-rich data. Increasing image resolution creates significant challenges. First, pretrained vision encoders often struggle with high-resolution images due to inefficient pretraining requirements. Running inference on high-resolution images increases computational costs and latency during visual token generation, whether through single high-resolution processing or multiple lower-resolution tile strategies. Second, high-resolution images produce more tokens, which leads to an increase in LLM prefilling time and time-to-first-token (TTFT), which is the sum of the vision encoder latency and the LLM prefilling time.
Large multimodal models such as Frozen and Florence used cross-attention to combine image and text embeddings within the intermediate LLM layers. Auto-regressive architectures like LLaVA, mPLUG-Owl, MiniGPT-4, and Cambrian-1 are effective. For efficient image encoding, CLIP-pretrained vision transformers remain widely adopted, with variants like SigLIP, EVA-CLIP, InternViT, and DFNCLIP. Methods like LLaVA-PruMerge and Matryoshka-based token sampling attempt dynamic token pruning, while hierarchical backbones such as ConvNeXT and FastViT reduce token count through progressive downsampling. Recently, ConvLLaVA was introduced, which uses a pure-convolutional vision encoder to encode images for a VLM.
Researchers from Apple have proposed FastVLM, a model that achieves an optimized tradeoff between resolution, latency, and accuracy by analyzing how image quality, processing time, number of tokens, and LLM size affect each other. It utilizes FastViTHD, a hybrid vision encoder designed to output fewer tokens and reduce encoding time for high-resolution images. FastVLM achieves an optimal balance between visual token count and image resolution only by scaling the input image. It shows a 3.2 times improvement in TTFT in the LLaVA1.5 setup and achieves superior performance on key benchmarks using the same 0.5B LLM when compared to LLaVA-OneVision at maximum resolution. It delivers 85 times faster TTFT while using a 3.4 times smaller vision encoder.
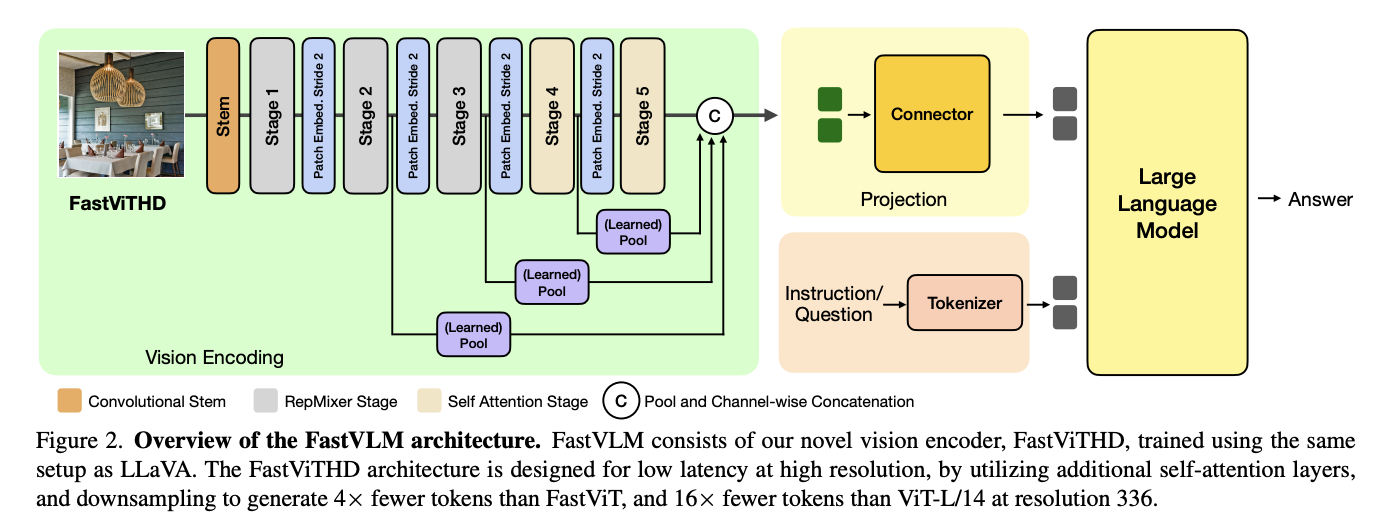
All FastVLM models are trained on a single node with 8 times NVIDIA H100-80GB GPUs, where stage 1 training of VLM is fast, taking around 30 minutes to train with a Qwen2-7B decoder. Further, FastViTHD enhances the base FastViT architecture by introducing an additional stage with a downsampling layer. This ensures self-attention operates on tensors downsampled by a factor of 32 rather than 16, reducing image encoding latency while generating 4 times fewer tokens for the LLM decoder. The FastViTHD architecture contains five stages: the first three stages utilize RepMixer blocks for efficient processing, while the final two stages employ multi-headed self-attention blocks, creating an optimal balance between computational efficiency and high-resolution image understanding.
When compared with ConvLLaVA using the same LLM and similar training data, FastVLM achieves 8.4% better performance on TextVQA and 12.5% improvement on DocVQA while operating 22% faster. The performance advantage increases at higher resolutions, where FastVLM maintains 2× faster processing speeds than ConvLLaVA across various benchmarks. FastVLM matches or surpasses MM1 performance across diverse benchmarks by using intermediate pretraining with 15M samples for resolution scaling, while generating 5 times fewer visual tokens. Moreover, FastVLM not only outperforms Cambrian-1 but also runs 7.9 times faster. With scaled instruction tuning, it delivers better results while using 2.3 times fewer visual tokens.

In conclusion, researchers introduced FastVLM, an advancement in VLM by utilizing the FastViTHD vision backbone for efficient high-resolution image encoding. The hybrid architecture, pretrained on reinforced image-text data, reduces visual token output while maintaining minimal accuracy sacrifice compared to existing approaches. FastVLM achieves competitive performance across VLM benchmarks while delivering notable efficiency improvements in both TTFT and vision backbone parameter count. Rigorous benchmarking on M1 MacBook Pro hardware shows that FastVLM offers a state-of-the-art resolution-latency-accuracy trade-off superior to the current methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
You may also like NVIDIA’s Open Sourced Cosmos DiffusionRenderer [Check it now]

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.




 Training")






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment