
 Training")



Building effective AI agents means more than just picking a powerful language model. As the Manus project discovered, how you design and manage the “context” – the information the AI processes to make decisions – is paramount. This “context engineering” directly impacts an agent’s speed, cost, reliability, and intelligence.
Initially, the choice was clear: leverage the in-context learning of frontier models over slow, iterative fine-tuning. This allows for rapid improvements, shipping changes in hours instead of weeks, making the product adaptable to evolving AI capabilities. However, this path proved far from simple, leading to multiple framework rebuilds through what they affectionately call “Stochastic Graduate Descent” – a process of experimental guesswork.
Here are the critical lessons learned at Manus for effective context engineering:
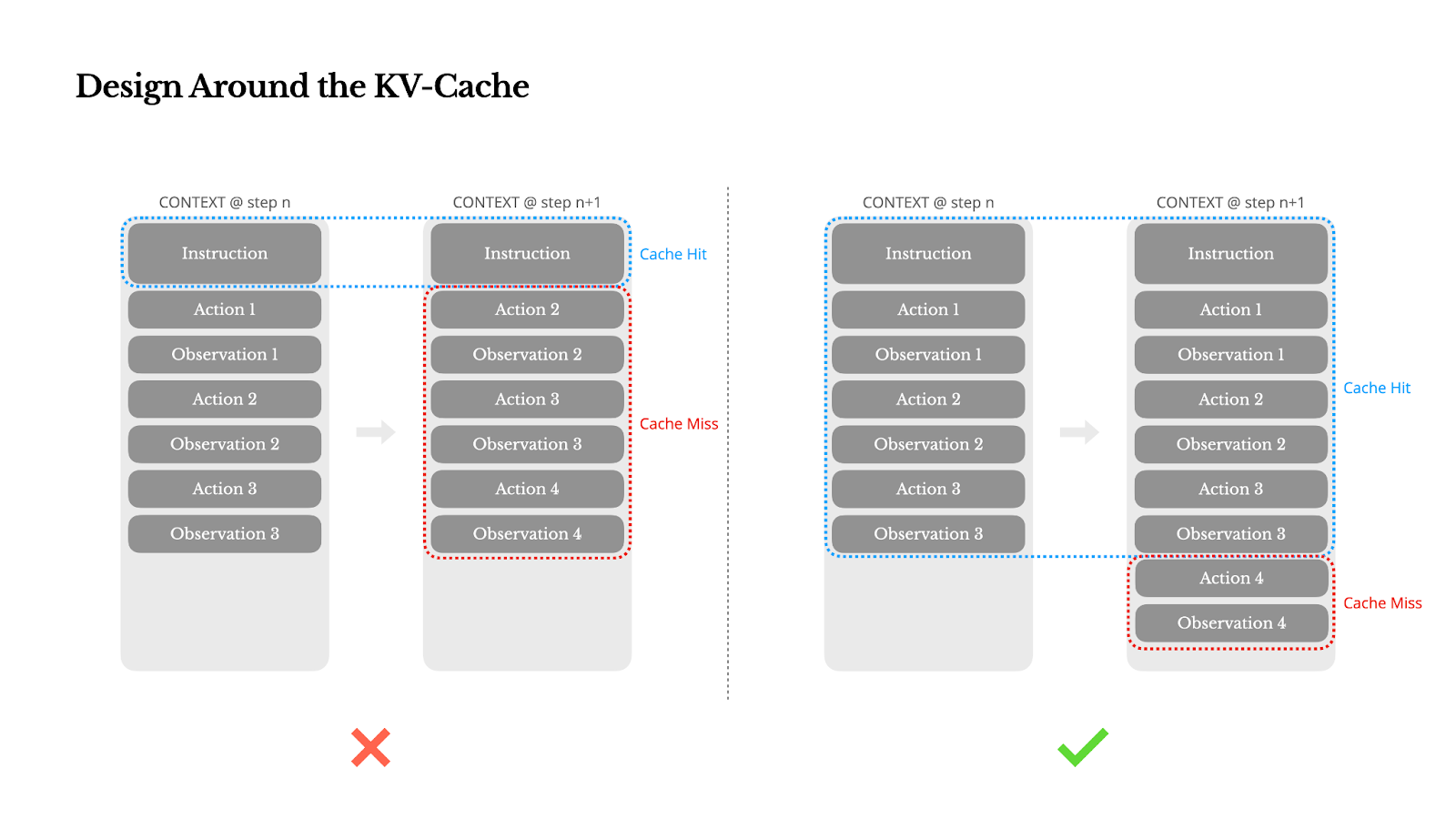
1. Design Around the KV-Cache
The KV-cache is vital for agent performance, directly affecting latency and cost. Agents continuously append actions and observations to their context, making the input significantly longer than the output. KV-cache reuses identical context prefixes, drastically reducing processing time and cost (e.g., a 10x cost difference with Claude Sonnet).

To maximize KV-cache hits:
- Stable Prompt Prefixes: Even a single-token change at the start of your system prompt can invalidate the cache. Avoid dynamic elements like precise timestamps.
- Append-Only Context: Do not modify past actions or observations. Ensure deterministic serialization of data (like JSON) to prevent subtle cache breaks.
- Explicit Cache Breakpoints: Some frameworks require manual insertion of cache breakpoints, ideally after the system prompt.
2. Mask, Don’t Remove
As agents gain more tools, their action space becomes complex, potentially “dumbing down” the agent as it struggles to choose correctly. While dynamic tool loading might seem intuitive, it invalidates the KV-cache and confuses the model if past context refers to undefined tools.
Manus instead uses a context-aware state machine to manage tool availability by masking token logits during decoding. This prevents the model from selecting unavailable or inappropriate actions without altering the core tool definitions, keeping the context stable and the agent focused.
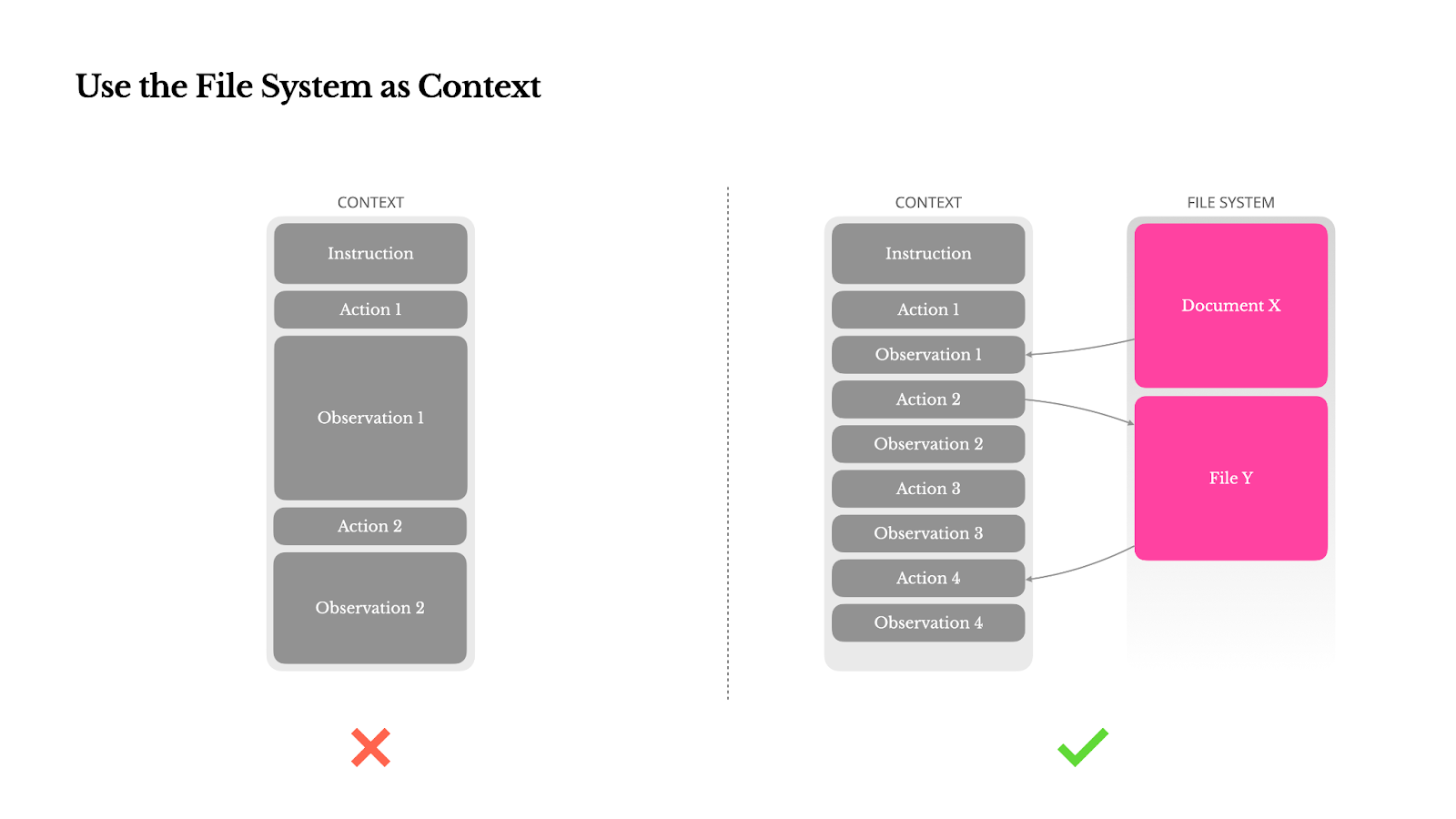
3. Use the File System as Context
Even with large context windows (128K+ tokens), real-world agentic observations (like web pages or PDFs) can easily exceed limits, degrade performance, and incur high costs. Irreversible compression risks losing crucial information needed for future steps.
Manus treats the file system as the ultimate, unlimited context. The agent learns to read from and write to files on demand, using the file system as externalized, structured memory.Compression strategies are always designed to be restorable (e.g., keeping a URL but dropping page content), effectively shrinking context length without permanent data loss.
4. Manipulate Attention Through Recitation
Agents can lose focus or forget long-term goals in complex, multi-step tasks. Manus tackles this by having the agent constantly rewrite a todo.md file. By reciting its objectives and progress into the end of the context, the model’s attention is biased towards its global plan, mitigating “lost-in-the-middle” issues and reducing goal misalignment. This leverages natural language to bias the AI’s focus without architectural changes.
5. Keep the Wrong Stuff In
Agents will make mistakes – hallucinate, encounter errors, misbehave. The natural impulse is to clean up these failures. However, Manus found that leaving failed actions and observations in the context implicitly updates the model’s internal beliefs. Seeing its own mistakes helps the agent learn and reduces the chance of repeating the same error, making error recovery a key indicator of true agentic behavior.
6. Don’t Get Few-Shotted
While few-shot prompting is powerful for LLMs, it can backfire in agents by leading to mimicry and sub-optimal, repetitive behavior. When the context is too uniform with similar action-observation pairs, the agent can fall into a rut, leading to drift or hallucination.
The solution is controlled diversity. Manus introduces small variations in serialization templates, phrasing, or formatting within the context. This “noise” helps break repetitive patterns and shifts the model’s attention, preventing it from getting stuck in a rigid imitation of past actions.
In conclusion, context engineering is very new but a critical field for AI agents. It goes beyond raw model power, dictating how an agent manages memory, interacts with its environment, and learns from feedback. Mastering these principles is essential for building robust, scalable, and intelligent AI agents.
Sponsorship Opportunity: Reach the most influential AI developers in US and Europe. 1M+ monthly readers, 500K+ community builders, infinite possibilities. [Explore Sponsorship]
Max is an AI analyst at MarkTechPost, based in Silicon Valley, who actively shapes the future of technology. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI daily to translate complex tech advancements into clear, understandable insights



 Training")






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment