

")

Machine Translation (MT) has emerged as a critical component of Natural Language Processing, facilitating automatic text conversion between languages to support global communication. While Neural Machine Translation (NMT) has revolutionized the field by employing deep learning techniques to capture complex linguistic patterns and contextual dependencies, significant challenges persist. Current NMT systems struggle with accurately translating idiomatic expressions, effectively handling low-resource languages with limited training data, and maintaining coherence across longer documents. These limitations substantially impact translation quality and usability in real-world scenarios.
LLMs like GPT-4, LLaMA, and Qwen have revolutionized MT, showing impressive capabilities in zero-shot and few-shot translation scenarios without requiring extensive parallel corpora. Such LLMs achieve performance comparable to supervised systems, offering versatility in style transfer, summarization, and question-answering tasks. Building upon LLMs, Large Reasoning Models (LRMs) represent the next evolutionary step in MT. LRMs integrate reasoning capabilities through techniques like Chain-of-Thought reasoning, approaching translation as a dynamic reasoning task rather than a simple mapping exercise. This approach enables LRMs to address persistent challenges in translation, including contextual coherence, cultural nuances, and compositional generalization.
Researchers from the MarcoPolo Team, Alibaba International Digital Commerce, and the University of Edinburgh present a transformative approach to MT by utilizing LRMs. Their position paper reframes translation as a dynamic reasoning task requiring deep contextual, cultural, and linguistic understanding rather than simple text-to-text mapping. The researchers identify three fundamental shifts enabled by LRMs, which are (a) contextual coherence for resolving ambiguities and preserving discourse structure across complex contexts, (b) cultural intentionality for adapting translations based on speaker intent and socio-linguistic norms, and (c) self-reflection capabilities that allow models to refine translations during inference iteratively. These shifts position LRMs as superior to both traditional NMT and LLM-based approaches.
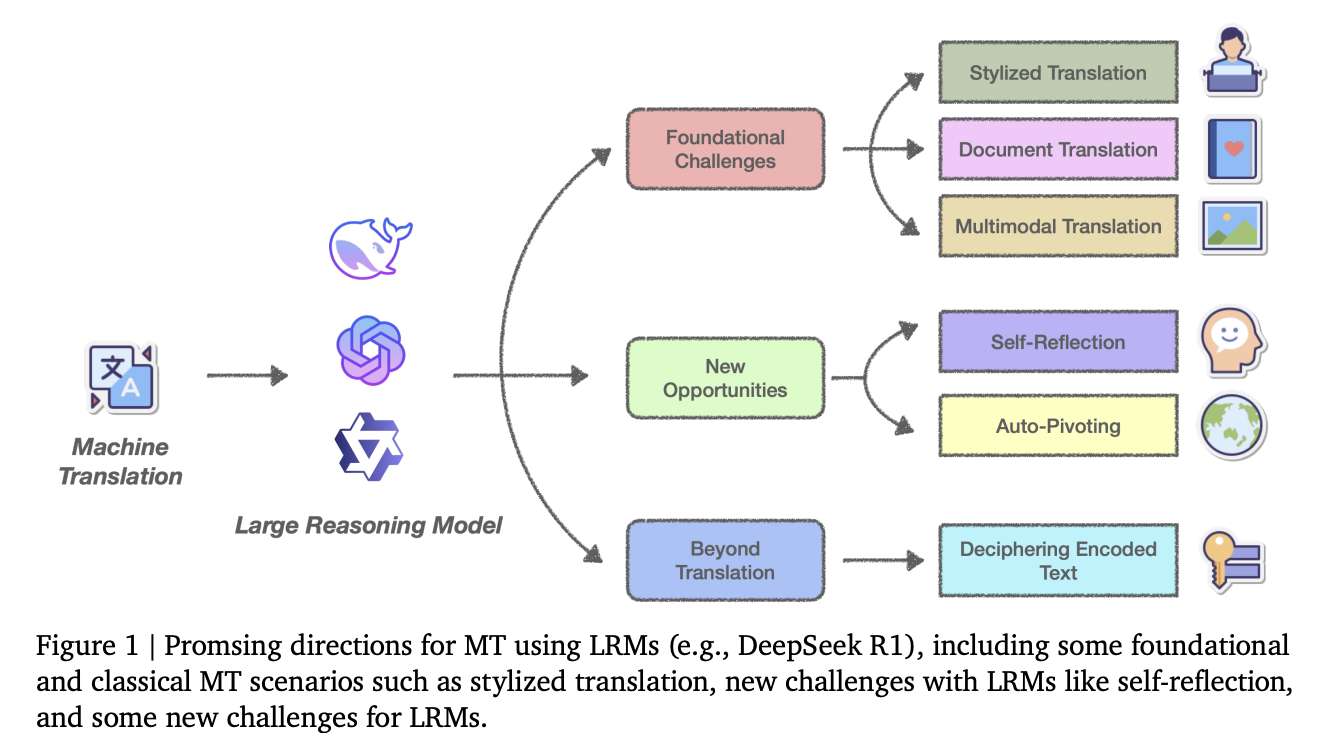
Characteristics of LRMs in MT include Self-reflection and Auto-pivot translation. Self-reflection enables the models to perform error detection and correction during the translation process, which is valuable when handling ambiguous or noisy inputs, such as text containing typos or scrambled sentences that conventional systems struggle to interpret accurately. In the Auto-pivot translation phenomenon, LRMs automatically utilize high-resource languages as intermediaries when translating between low-resource language pairs, e.g., when translating from Irish to Chinese, the model internally reasons through English before generating the final output. However, this approach introduces potential challenges regarding computational efficiency and possible distortions when equivalent expressions don’t exist in the pivot language.
When evaluated using metrics like BLEURT and COMET, no significant differences emerged between the four models tested, but models with lower scores produced better translations. For instance, DeepSeek-R1 generated superior translations compared to DeepSeek-V3. Moreover, the reasoning-enhanced models generate more diverse translations that may differ from reference translations while maintaining accuracy and natural expression. For example, for the sentence “正在采收的是果园里的 果农,” the reference translation is “The orchard worker in the orchard is harvesting.” DeepSeek-R1 translated it as “The orchard farmers are harvesting”, with a 0.7748 COMET score, and the translation generated by DeepSeek-V3 is “The orchard farmers are currently harvesting the fruits”, which received a COMET score of 0.8039.
In this paper, researchers have explored the transformative potential of LRMs in MT. LRMs effectively address long-standing challenges using reasoning capabilities, including stylized translation, document-level translation, and multi-modal translation, while introducing innovative capabilities like self-reflection and auto-pivot language translation. However, significant limitations persist, particularly in complex reasoning tasks and specialized domains. While LRMs can successfully decipher simple ciphers, they struggle with complex cryptographic challenges and may generate hallucinated content when facing uncertainty. Future research includes improving LRM robustness when handling ambiguous or computationally intensive tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.






")



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment