



Visual generative models have advanced significantly in terms of the ability to create high-quality images and videos. These developments, powered by AI, enable applications ranging from content creation to design. However, the capability of these models depends on the evaluation frameworks used to measure their performance, making efficient and accurate assessments a crucial area of focus.
Existing evaluation frameworks for visual generative models are often inefficient, requiring significant computational resources and rigid benchmarking processes. To measure performance, traditional tools rely heavily on large datasets and fixed metrics, such as FID and FVD. These methods lack flexibility and adaptability, often producing simple numerical scores without deeper interpretive insights. This creates a gap between the evaluation process and user-specific requirements, limiting their practicality in real-world applications.
Traditional benchmarks like VBench and EvalCrafter focus on specific dimensions such as subject consistency, aesthetic quality, and motion smoothness. However, these methods demand thousands of samples for evaluation, leading to high time costs. For instance, benchmarks like VBench require up to 4,355 samples per evaluation, consuming over 4,000 minutes of computation time. Despite their comprehensiveness, these frameworks struggle to adapt to user-defined criteria, leaving room for improvement in efficiency and flexibility.
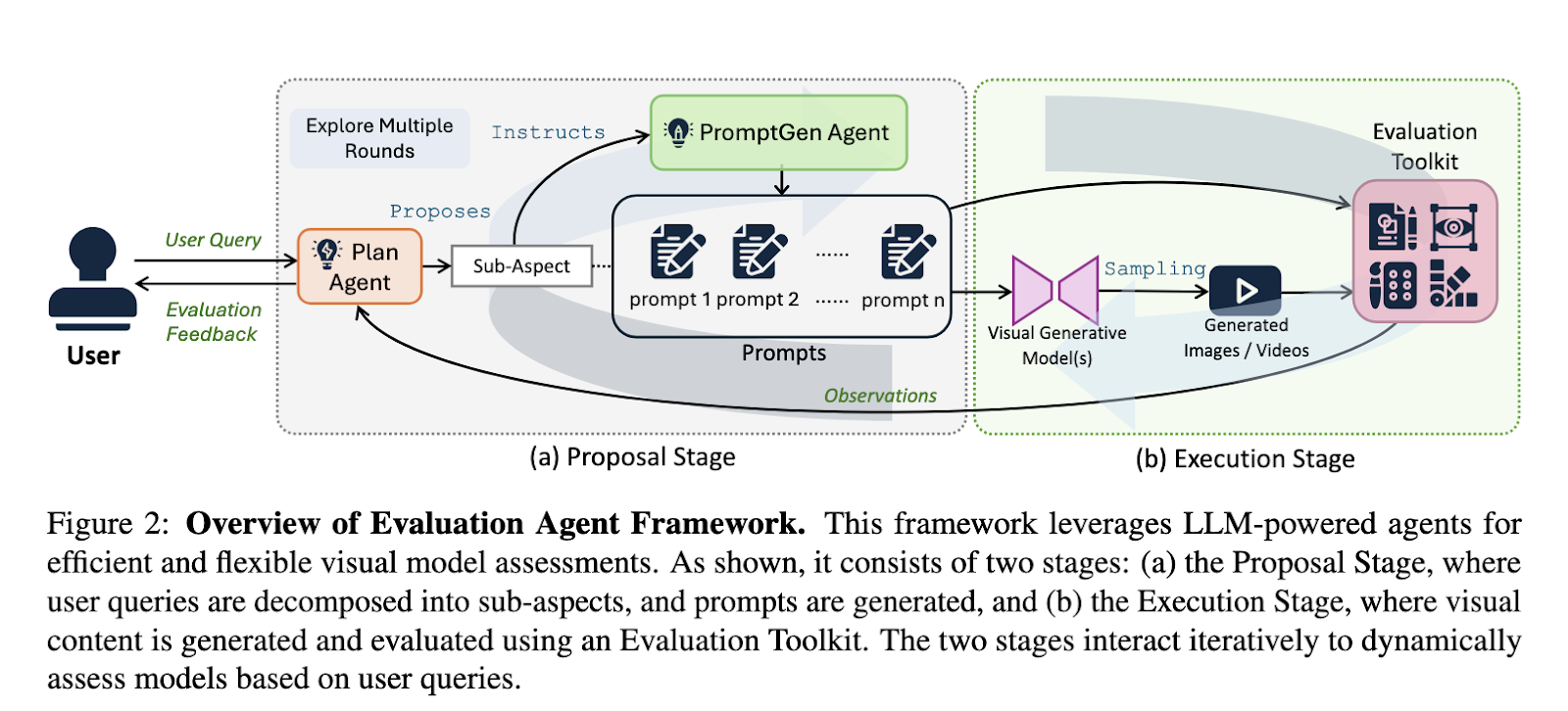
Researchers from the Shanghai Artificial Intelligence Laboratory and Nanyang Technological University introduced the Evaluation Agent framework to address these limitations. This innovative solution mimics human-like strategies by conducting dynamic, multi-round evaluations tailored to user-defined criteria. Unlike rigid benchmarks, this approach integrates customizable evaluation tools, making it adaptable and efficient. The Evaluation Agent leverages large language models (LLMs) to power its intelligent planning and dynamic evaluation process.
The Evaluation Agent operates through two stages. The system identifies evaluation dimensions based on user input in the Proposal Stage and dynamically selects test cases. Prompts are generated by the PromptGen Agent, which designs tasks aligned with the user’s query. The Execution Stage involves generating visuals based on these prompts and evaluating them using an extensible toolkit. The framework eliminates redundant test cases and uncovers nuanced model behaviors by dynamically refining its focus. This dual-stage process allows for efficient evaluations while maintaining high accuracy.
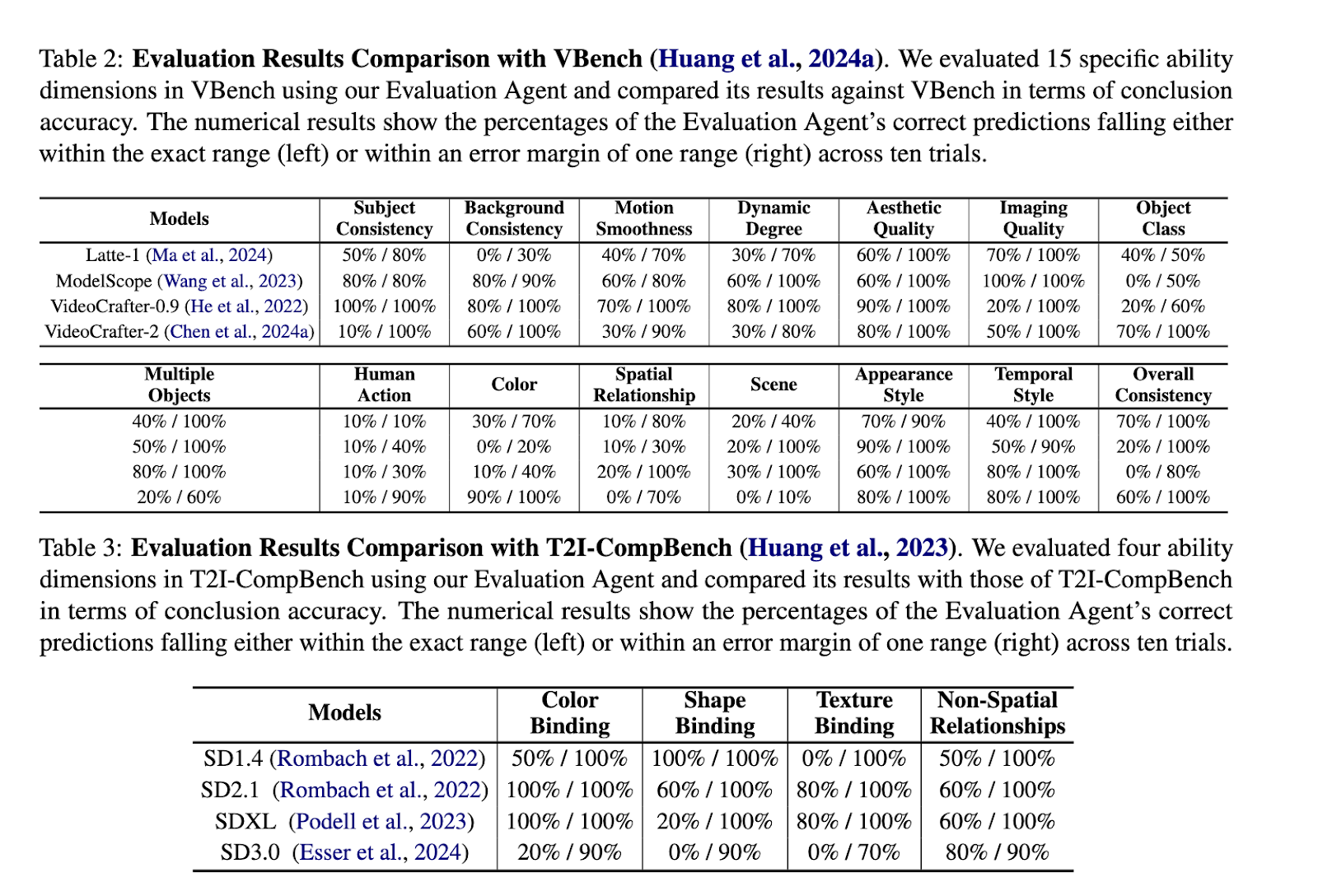
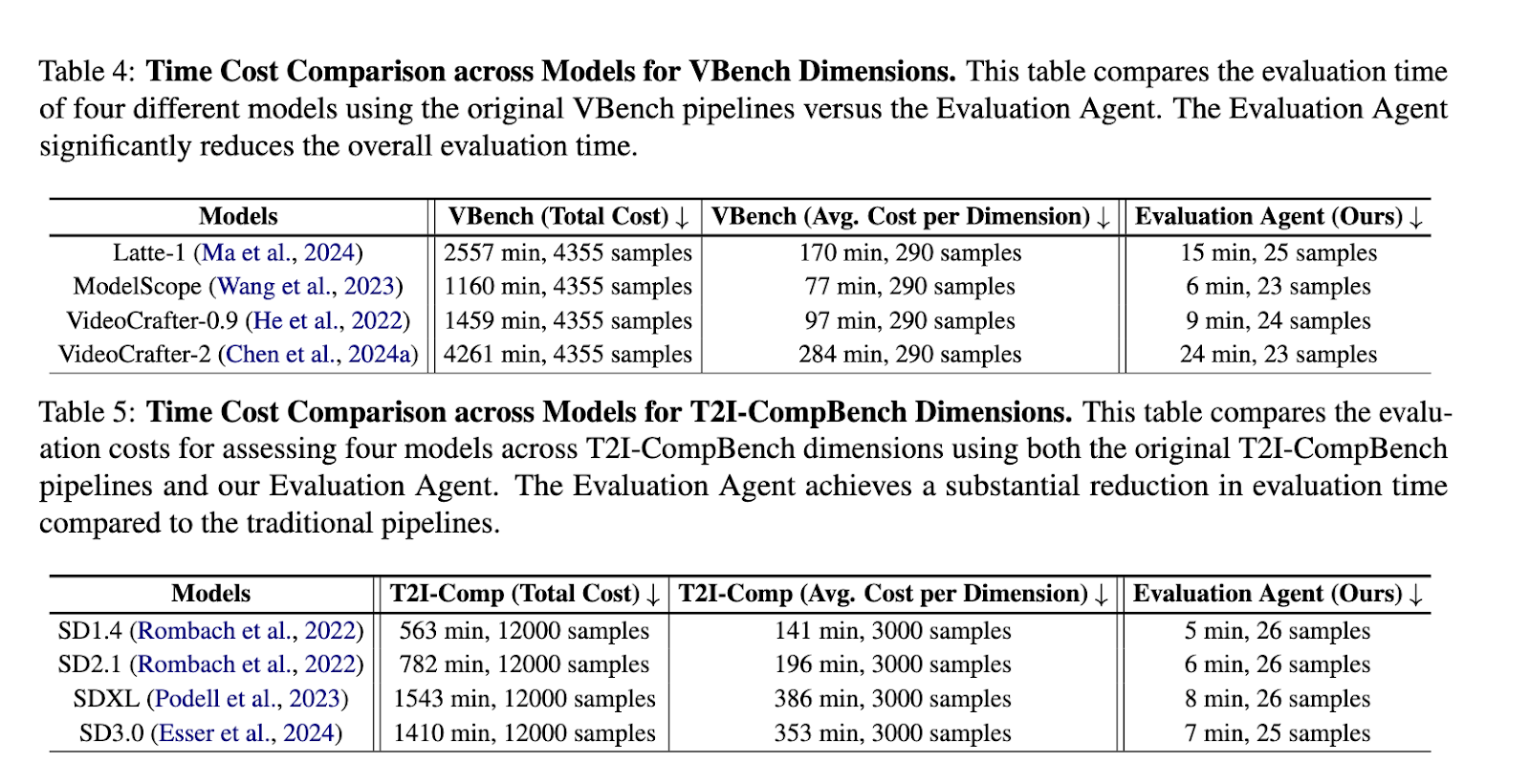
The framework significantly outperforms traditional methods in terms of efficiency and adaptability. While benchmarks like VBench require thousands of samples and over 4,000 minutes to complete evaluations, the Evaluation Agent achieves similar accuracy using only 23 samples and 24 minutes per model dimension. Across various dimensions, such as aesthetic quality, spatial relationships, and motion smoothness, the Evaluation Agent demonstrated prediction accuracy comparable to established benchmarks while reducing computational costs by over 90%. For instance, the system evaluated models like VideoCrafter-2.0 with a consistency of up to 100% in multiple dimensions.
The Evaluation Agent achieved remarkable results in its experiments. It adapted to user-specific queries, providing detailed, interpretable results beyond numerical scores. It also supported evaluations across text-to-image (T2I) and text-to-video (T2V) models, highlighting its scalability and versatility. Considerable reductions in evaluation time were observed, from 563 minutes with T2I-CompBench to just 5 minutes for the same task using the Evaluation Agent. This efficiency positions the framework as a superior alternative for evaluating generative models in academic and industrial contexts.
The Evaluation Agent offers a transformative approach to visual generative model evaluation, overcoming the inefficiencies of traditional methods. By combining dynamic, human-like evaluation processes with advanced AI technologies, the framework provides a flexible and accurate solution for assessing diverse model capabilities. The substantial reduction in computational resources and time costs highlights its potential for broad adoption, paving the way for more effective evaluations in generative AI.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
")






 Servers Worth Exploring")


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment