



Foundation models show impressive capabilities across tasks and modalities, outperforming traditional AI approaches often task-specific and limited by modality. In medicine, however, developing such models faces challenges due to restricted access to diverse data and strict privacy laws. While capable in specific areas, existing medical foundation models need to be improved by their focus on particular tasks and modalities. The limitations include difficulties in centralized training due to privacy laws like HIPAA and GDPR and limited adaptability across functions. Federated learning offers a solution, enabling decentralized model development without sharing sensitive data directly while incorporating broader medical knowledge, which remains an ongoing challenge.
Foundation models, with vast parameters and datasets, have become prominent in healthcare, offering solutions for tasks like disease detection and precision oncology. Despite these advances, medical foundation models are limited by the complexities of healthcare data. Federated learning (FL) enables fine-tuning foundation models with locally stored data, supporting full or parameter-efficient fine-tuning (PEFT) methods like Low-Rank Adaptation (LoRA), which reduces computational demands by factorizing parameters. While Mixture of Experts (MOE) approaches further refine PEFT for complex tasks, existing methods don’t fully address the diverse, multimodal needs unique to healthcare settings.
Researchers from Pennsylvania State University and Georgia State University have developed FEDKIM, an innovative knowledge injection method to expand medical foundation models within a federated learning framework. FEDKIM uses lightweight local models to gather healthcare insights from private data, which are incorporated into a centralized foundation model. This is achieved through the Multitask Multimodal Mixture of Experts (M3OE) module, which adapts to different medical tasks and modalities while safeguarding data privacy. Experiments on twelve tasks across seven modalities confirm FEDKIM’s capability to scale medical foundation models effectively, even without direct access to sensitive data.
The FEDKIM framework comprises two main components: local client knowledge extractors and a central server-side knowledge injector. Each client, representing a hospital or medical institute, trains a multimodal, multi-task model on private data, which is then shared with the server. These client parameters are aggregated and injected into a central medical foundation model on the server, enhanced with a Multitask M3OE module. This module dynamically selects expert systems for each task-modality pair, allowing FEDKIM to handle complex medical scenarios. This iterative process updates local and server models, enabling efficient knowledge integration and privacy preservation.
The study assesses FEDKIM’s performance through zero-shot and fine-tuning evaluations. In zero-shot tests, where training and evaluation tasks differ, FEDKIM outperformed baselines like FedPlug and FedPlugL, particularly in handling unseen tasks, due to its M3OE module that selects experts adaptively. FEDKIM also showed strong performance with both FedAvg and FedProx backbones, though FedProx generally enhanced results. Fine-tuning evaluation on known tasks confirmed FEDKIM’s superior performance, especially over FedPlug variants, as knowledge injected through federated learning proved valuable. Ablation studies underscored the necessity of FEDKIM’s modules, validating their importance in handling complex healthcare tasks and modalities.
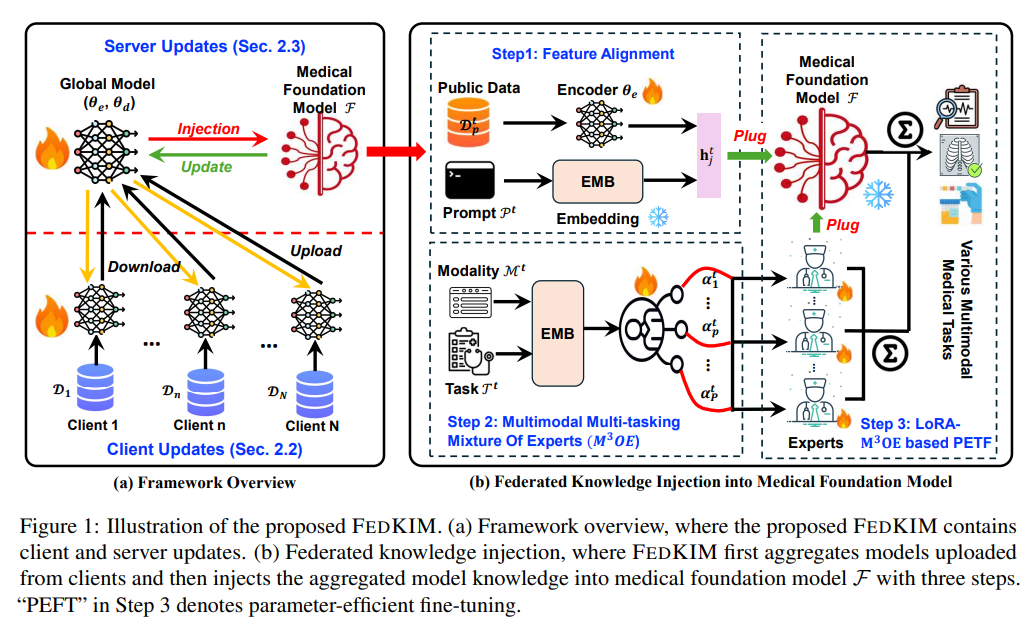
In conclusion, the study introduces FEDKIM, an approach for enhancing medical foundation models through knowledge injection. FEDKIM utilizes federated learning to extract knowledge from safely distributed private healthcare data. It integrates it into a central model using the M3OE module, which adapts to handle diverse tasks and modalities. This technique addresses challenges in medical AI, such as privacy constraints and limited data access, while improving model performance across complex tasks. Experimental results across 12 tasks and seven modalities confirm FEDKIM’s effectiveness, highlighting its potential for building comprehensive, privacy-preserving healthcare models without direct access to sensitive data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment