

")

Google AI has just unveiled Gemini 2.5 Flash Image, a new generation image model designed to let users generate and edit images simply by describing them—and its true innovation is how it delivers precise, consistent, and high-fidelity edits at impressive speed and scale.
What Makes Gemini 2.5 Flash Image Impressive?
Gemini 2.5 Flash Image is built on the multimodal, advanced reasoning foundation of Gemini 2.5, (meaning it natively understands both images and text) enabling seamless workflows for generation and editing. This architecture allows users to:
- Blend multiple images into one with a single prompt
- Maintain subject and character consistency across many edits
- Make targeted, natural language-driven transformations (e.g. “change the shirt color,” “remove person from photo”)
- Retain context and visual fidelity through iterative revisions—regardless of the complexity or diversity of edits
This is a leap beyond older image models, which often struggled to maintain identity or visual coherence when making edits or compositing scenes.
Key Technical Features
- Precise visual editing: The model supports highly accurate, localized edits based on natural language prompts, from background blurring to pose adjustments and object removals.
- Multimodal fusion: Accepts multiple reference images and fuses them, enabling, for instance, complex product mockups or multi-character scenes in advertising.
- Template/brand consistency: Gemini 2.5 Flash Image preserves styling, branding, and character consistency across generated assets or product catalogs.
- Advanced reasoning: Taps into Gemini’s semantic world knowledge for tasks like diagram understanding or educational annotation—not just photorealistic rendering.
- Scalable API availability: Developers and enterprises can access the model via Gemini API, Google AI Studio, and Vertex AI—with built-in SynthID watermarking for AI provenance and regulatory compliance.
Benchmark Leadership and Community Reception
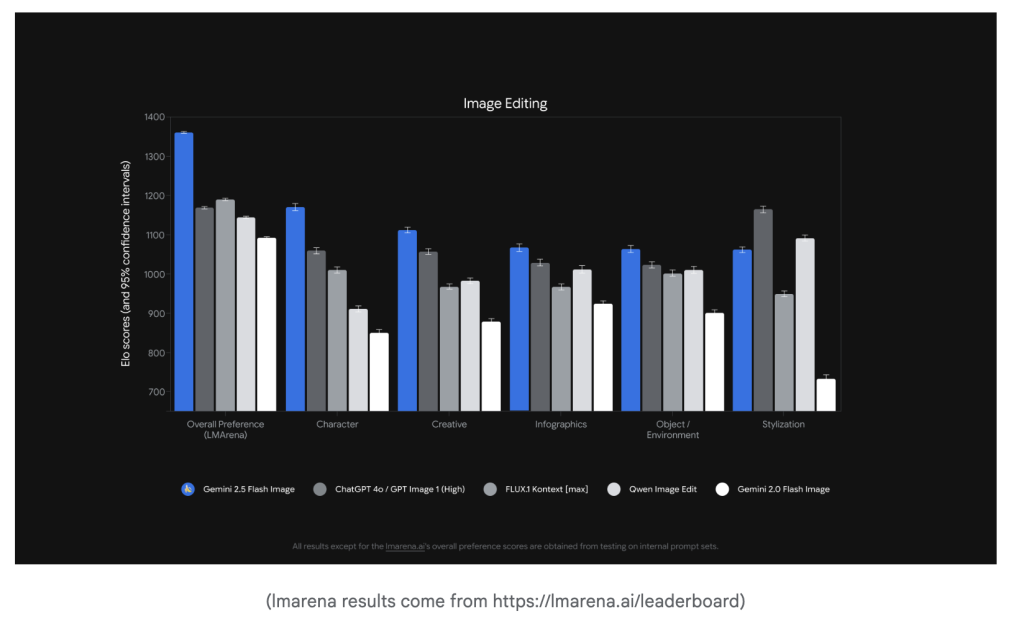
Gemini 2.5 Flash Image has quickly led public benchmarks, topping LMArena for prompt adherence and edit quality, surpassing competitors like GPT-4o’s native image tools and FLUX AI image models. Enthusiasts and experts highlight its photorealism, but also its remarkable semantic control—making edits that look natural and true to the source material even across multiple iterations.
Pricing, Access, and Future Roadmap
The model is available in preview for $0.039 per image via Gemini API, Google AI Studio, and Vertex AI, with enterprise and developer integration rising rapidly thanks to partnerships with platforms like OpenRouter and fal.ai. All generated images feature invisible SynthID watermarks for traceability and AI ethics compliance, and Google is actively improving long-form text rendering and even finer consistency.
In Summary:
Gemini 2.5 Flash Image isn’t just faster and more creative, it’s technically “a-peel-ing” because it finally solves the long-standing challenge of consistent, context-aware image editing in generative AI—unlocking powerful new workflows for creators, developers, and enterprises.
FAQs
What is Gemini 2.5 Flash Image?
Gemini 2.5 Flash Image is Google’s state-of-the-art AI model for generating and editing images with natural language prompts, supporting multimodal fusion and advanced reasoning for precise, consistent edits.
How do you edit images using Gemini 2.5 Flash Image?
Simply describe the changes needed in natural language, such as “remove a person from the photo” or “change shirt color,” and the model applies edits while preserving key visual details and scene consistency.
Where can users access the model?
Gemini 2.5 Flash Image is available in the Gemini app, Google AI Studio, Vertex AI, and via API for developers and enterprises; it’s also integrated in platforms like Adobe Firefly and Express.
Which file formats does Gemini 2.5 Flash Image support?
By default, images are generated in JPEG format rather than PNG or WebP, reflecting optimization for broad compatibility and file size.
Are there safeguards for image generation?
Google employs strict safety features and content filters to prevent the creation of harmful or inappropriate visuals, balancing creative control with responsible AI use.
Check out the Technical details here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.





?: Top MLSecOps Tools (2025)")



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment