



Reinforcement Learning RL trains agents to maximize rewards by interacting with an environment. Online RL alternates between taking actions, collecting observations and rewards, and updating policies using this experience. Model-free RL (MFRL) maps observations to actions but requires extensive data collection. Model-based RL (MBRL) mitigates this by learning a world model (WM) for planning in an imagined environment. Standard benchmarks like Atari-100k test sample efficiency, but their deterministic nature allows memorization rather than generalization. To encourage broader skills, researchers use Crafter, a 2D Minecraft-like environment. Craftax-classic, a JAX-based version, introduces procedural environments, partial observability, and a sparse reward system, requiring deep exploration.
MBRL methods vary based on how WMs are used—for background planning (training policies with imagined data) or decision-time planning (conducting lookahead searches during inference). As seen in MuZero and EfficientZero, decision-time planning is effective but computationally expensive for large WMs like transformers. Background planning, originating from Dyna-Q learning, has been refined in deep RL models like Dreamer, IRIS, and DART. WMs also differ in generative ability; while non-generative WMs excel in efficiency, generative WMs better integrate real and imagined data. Many modern architectures use transformers, though recurrent state-space models like DreamerV2/3 remain relevant.
Researchers from Google DeepMind introduce an advanced MBRL method that sets a new benchmark in the Craftax-classic environment, a complex 2D survival game requiring generalization, deep exploration, and long-term reasoning. Their approach achieves a 67.42% reward after 1M steps, surpassing DreamerV3 (53.2%) and human performance (65.0%). They enhance MBRL with a robust model-free baseline, “Dyna with warmup” for real and imagined rollouts, a nearest-neighbor tokenizer for patch-based image processing, and block teacher forcing for efficient token prediction. These refinements collectively improve sample efficiency, achieving state-of-the-art performance in data-efficient RL.
The study enhances the MFRL baseline by expanding the model size and incorporating a Gated Recurrent Unit (GRU), increasing rewards from 46.91% to 55.49%. Additionally, the study introduces an MBRL approach using a Transformer World Model (TWM) with VQ-VAE quantization, achieving 31.93% rewards. To further optimize performance, a Dyna-based method integrates real and imagined rollouts, improving learning efficiency. Replacing VQ-VAE with a patch-wise nearest-neighbor tokenizer boosts performance from 43.36% to 58.92%. These advancements demonstrate the effectiveness of combining memory mechanisms, transformer-based models, and improved observation encoding in reinforcement learning.
The study presents results from experiments on the Craftax-classic benchmark, conducted on 8 H100 GPUs over 1M steps. Each method collected 96-length trajectories in 48 parallel environments. For MBRL methods, imaginary rollouts were generated at 200k environment steps and updated 500 times. The “MBRL ladder” progression showed significant improvements, with the best agent (M5) achieving a 67.42% reward. Ablation studies confirmed the importance of each component, such as Dyna, NNT, patches, and BTF. Compared with existing methods, the best MBRL agent achieved a state-of-the-art performance. Additionally, Craftax Full experiments demonstrated generalization to harder environments.
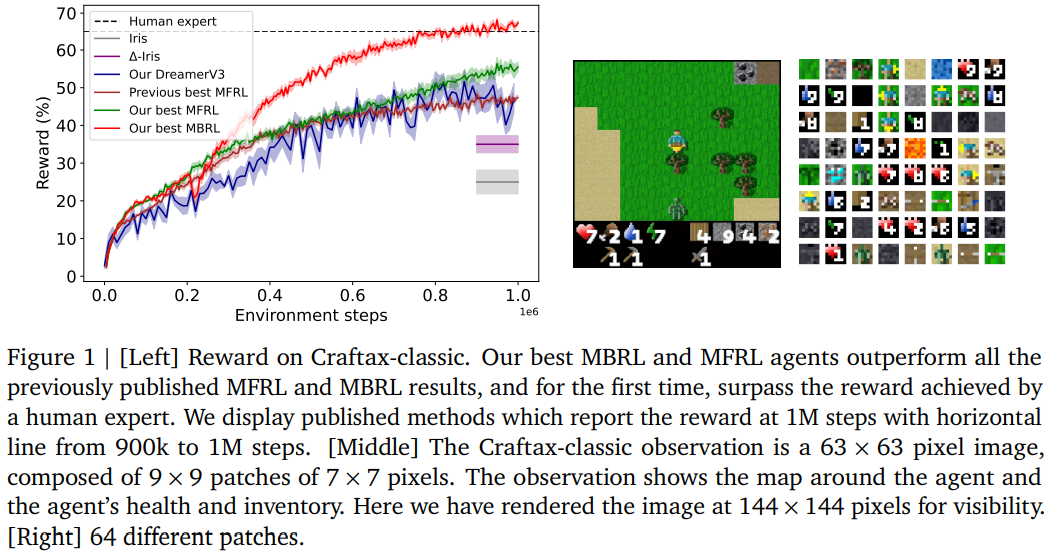
In conclusion, the study introduces three key improvements to vision-based MBRL agents using TWM for background planning. These enhancements include Dyna with warmup, patch nearest-neighbor tokenization, and block teacher forcing. The proposed MBRL agent performs better on the Craftax-classic benchmark, surpassing previous state-of-the-art models and human expert rewards. Future work includes exploring generalization beyond Craftax, prioritizing experience replay, integrating off-policy RL algorithms, and refining the tokenizer for large pre-trained models like SAM and Dino-V2. Additionally, the policy will be modified to accept latent tokens from non-reconstructive world models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment