
")


Regression tasks, which involve predicting continuous numeric values, have traditionally relied on numeric heads such as Gaussian parameterizations or pointwise tensor projections. These traditional approaches have strong distributional assumption requirements, require a lot of labeled data, and tend to break down when modeling advanced numerical distributions. New research on large language models introduces a different approach—representing numerical values as sequences of discrete tokens and using auto-regressive decoding for prediction. This shift, however, comes with several serious challenges, including the need for an efficient tokenization mechanism, the potential for numeric precision loss, the need to maintain stable training, and the need to overcome the lack of inductive bias of sequential token forms for numerical values. Overcoming these challenges would lead to an even more powerful, data-efficient, and flexible regression framework, thus extending the application of deep learning models beyond traditional approaches.
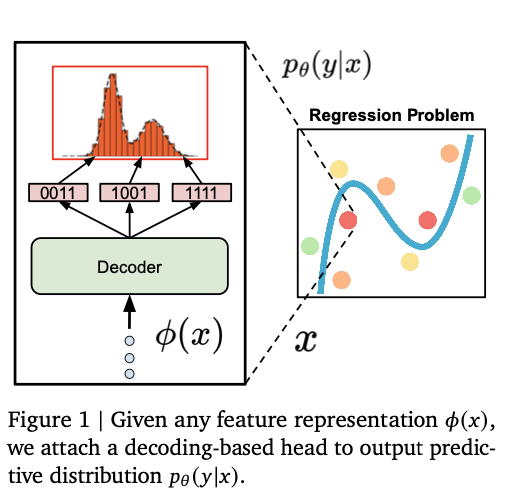
Traditional regression models rely on numeric tensor projections or parametric distributional heads, such as Gaussian models. While these conventional approaches are widespread, they also have several drawbacks. Gaussian-based models have the drawback of assuming normally distributed outputs, restricting the ability to model more advanced, multimodal distributions. Pointwise regression heads struggle with highly non-linear or discontinuous relationships, which restricts their ability to generalize on various datasets. High-dimensional models, such as histogram-based Riemann distributions, are computationally and data-intensive and, therefore, inefficient. Furthermore, many traditional approaches require explicit normalization or scaling of output, introducing an additional layer of complexity and potential instability. While conventional work has tried to employ text-to-text regression using large language models, little systematic work has been done on “anything-to-text” regression, where numeric outputs are represented as sequences of tokens, thus introducing a new paradigm for numerical prediction.
Researchers from Google DeepMind propose an alternative regression formulation, reframing numeric prediction as an auto-regressive sequence generation problem. Instead of generating scalar values directly, this method encodes numbers as token sequences and employs constrained decoding to generate valid numerical outputs. Encoding numeric values as discrete token sequences makes this method more flexible and expressive when modeling real-valued data. Unlike Gaussian-based approaches, this method does not entail strong distributional assumptions about data, thus making it more generalizable to real-world tasks with heterogeneous patterns. The model accommodates precise modeling of multimodal, complex distributions, thus improving its performance in density estimation as well as pointwise regression tasks. By leveraging the advantages of autoregressive decoders, it takes advantage of recent language modeling progress while still retaining competitive performance relative to standard numeric heads. This formulation presents a robust and flexible framework that can model a wide range of numeric relationships precisely, offering a practical substitute to standard regression methods that are usually regarded as inflexible.
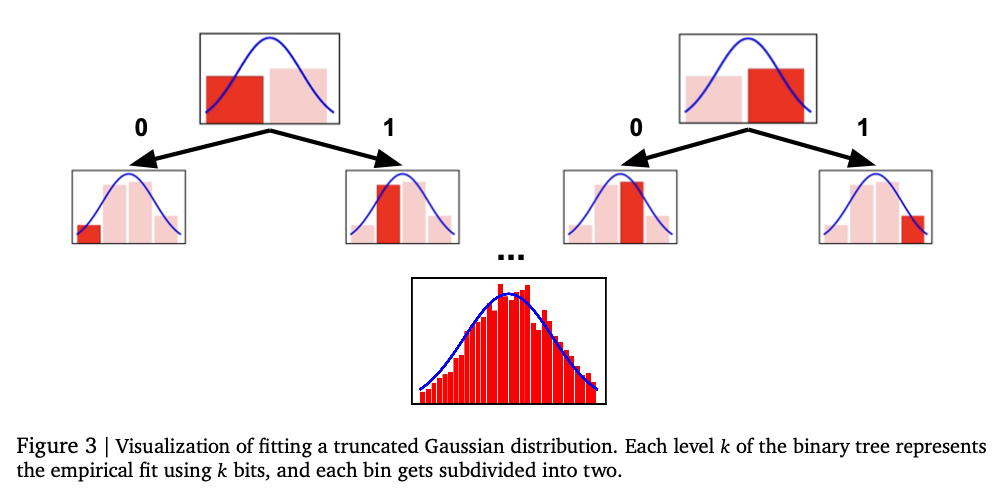
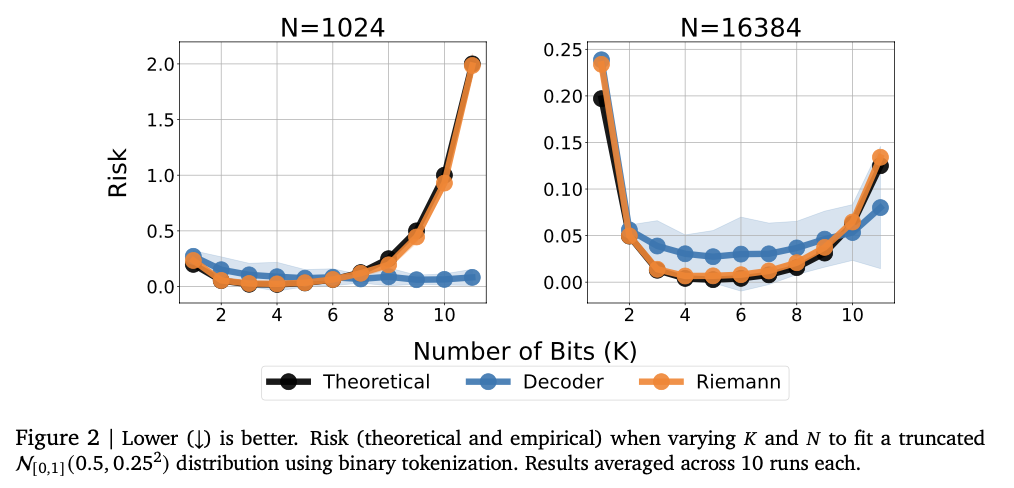
The approach employs two tokenization methods for numeric representation: normalized tokenization and unnormalized tokenization. Normalized tokenization encodes numbers in a fixed range with base-B expansion to provide finer precision with increasing sequence length. Unnormalized tokenization extends the same idea to broader numeric ranges with a generalized floating-point representation such as IEEE-754 without the necessity of explicit normalization. A transformer auto-regressive model generates numeric outputs token by token subject to constraints to provide valid numeric sequences. The model is trained using cross-entropy loss over the token sequence to provide accurate numeric representation. Instead of predicting a scalar output directly, the system samples token sequences and employs statistical estimation techniques, such as mean or median computation, for final prediction. Evaluations are conducted on real-world tabular regression datasets of OpenML-CTR23 and AMLB benchmarks and compared with Gaussian mixture models, histogram-based regression, and standard pointwise regression heads. Hyperparameter tuning is conducted across various decoder settings, such as variations in the number of layers, hidden units, and token vocabularies, to provide optimized performance.
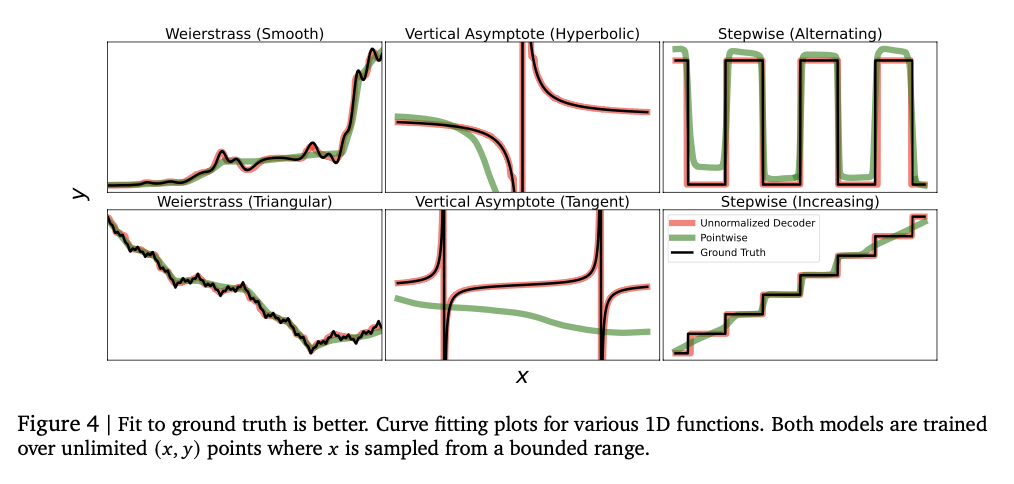
Experiments show that the model successfully captures intricate numeric relationships, achieving strong performance on a variety of regression tasks. It attains high Kendall-Tau correlation scores on tabular regression, often outperforming baseline models, especially in low-data settings where numeric stability is essential. The method is also better in density estimation, successfully capturing intricate distributions and outperforming Gaussian mixture models and Riemann-based approaches in negative log-likelihood tests. Model size tuning at the start improves performance, with overcapacity causing overfitting. Numeric stability is greatly improved by error correction methods like token repetition and majority voting, minimizing vulnerability to outliers. These results make this regression framework a robust and adaptive alternative to traditional methods, showing its capacity to successfully generalize across various datasets and modeling tasks.
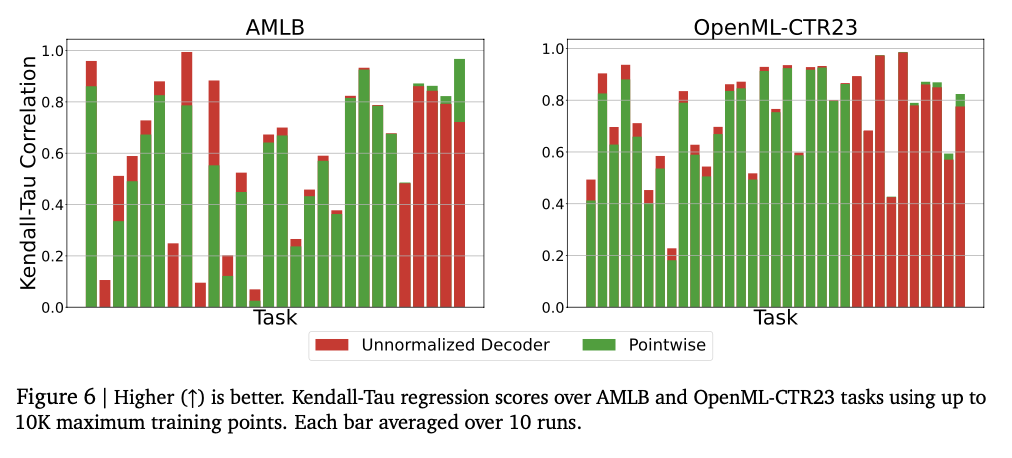
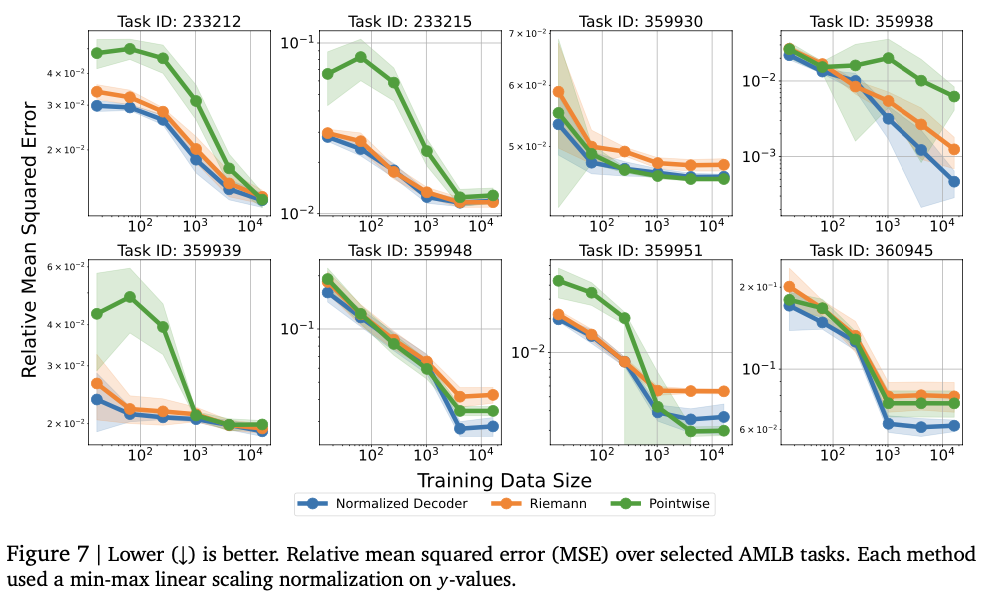
This work introduces a novel approach to numeric prediction by leveraging tokenized representations and auto-regressive decoding. By substituting traditional numeric regression heads with token-based outputs, the framework improves flexibility in modeling real-valued data. It attains competitive performance on various regression tasks, especially in density estimation and tabular modeling, while providing theoretical guarantees for approximating arbitrary probability distributions. It outperforms traditional regression methods in important contexts, especially in modeling intricate distributions and sparse training data. Future work involves improving tokenization methods for better numeric precision and stability, extending the framework to multi-output regression and high-dimensional prediction tasks, and investigating its applications in reinforcement learning reward modeling and vision-based numeric estimation. These results make sequence-based numeric regression a promising alternative to traditional methods, expanding the scope of tasks that language models can successfully solve.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
: A Class of Trainable Deep Learning-based Geometries that can Universally Represent Nodes in Weighted Directed Acyclic Graphs (DAGs) as Events in a Spacetime Manifold")


")


")



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment