
")


Multi-agent pathfinding (MAPF), within computer science and robotics, deals with the problem of routing multiple agents, such as robots, to their individual goals within a shared environment. These agents must find collision-free paths while maintaining a high level of efficiency. MAPF is crucial for applications such as automated warehouses, traffic management, and drone fleets. The complexity of the problem increases with the number of agents, making real-time solutions necessary for practical use.
A significant challenge researchers face in MAPF is managing the complexity and computational demand of routing multiple agents without collisions, especially as the number of agents increases. The computational difficulty of solving MAPF optimally makes it NP-hard, meaning it is almost impossible to find a perfectly optimal solution in a reasonable time for large-scale problems. Traditional methods struggle with these issues, often relying on oversimplified assumptions or excessive computational resources. Another challenge is the agents’ limited view of their environment, which makes decentralized decision-making difficult without a global view or real-time communication.
Over the years, researchers have explored several approaches to solve MAPF. Rule-based solvers, graph-based methods, and optimization techniques such as minimum flow on graphs are common. These approaches attempt to simplify the problem by transforming it into another, more solvable type of problem or by applying graph search techniques to find paths. More recent methods have incorporated machine learning and deep reinforcement learning, where agents learn from their environment and adjust their paths accordingly. However, these methods often require communication between agents or rely on heuristics to enhance performance, which adds layers of complexity to an already difficult problem.

The research team from AIRI, the Federal Research Center “Computer Science and Control” of the Russian Academy of Sciences, and the Moscow Institute of Physics and Technology introduced an innovative approach to solving MAPF called MAPF-GPT. This method stands out because it utilizes a transformer-based model trained through imitation learning. MAPF-GPT is decentralized, meaning each agent makes decisions independently, relying on local observations. Unlike previous methods, MAPF-GPT does not require communication between agents or additional planning steps, making it more scalable and efficient. The team also used a large dataset of expert trajectories, allowing the model to learn from sub-optimal solutions and still perform well in unseen environments.
In developing MAPF-GPT, the researchers created a comprehensive dataset of sub-optimal MAPF solutions generated by existing solvers. These solutions were converted into sequences of observations and actions, referred to as tokens, from which the model could learn. Using a neural network architecture known as transformers, MAPF-GPT could predict the correct actions for agents based on their observations. The local observation for each agent included the current map layout and the agent’s position relative to obstacles and other agents. The model was trained using cross-entropy loss, which allowed it to optimize its decision-making process based on the observed actions from expert data. The researchers ensured that the dataset was diverse, containing over 1 billion observation-action pairs from a variety of MAPF scenarios, including mazes and random maps.
The performance of MAPF-GPT was thoroughly evaluated against other state-of-the-art decentralized MAPF solvers, including DCC and SCRIMP. In terms of success rate, MAPF-GPT outperformed these models across several scenarios. For example, the largest version of the model, MAPF-GPT-85M, achieved a significantly higher success rate on random maps and maze-like environments compared to its competitors. It was also shown that MAPF-GPT-85M solved problems involving up to 192 agents with linear scalability, meaning its computational requirements increased predictably as the number of agents grew. The model proved to be 13 times faster than SCRIMP and 8 times faster than DCC in high-agent environments. This was particularly evident in large-scale warehouse simulations, where MAPF-GPT demonstrated both speed and efficiency.
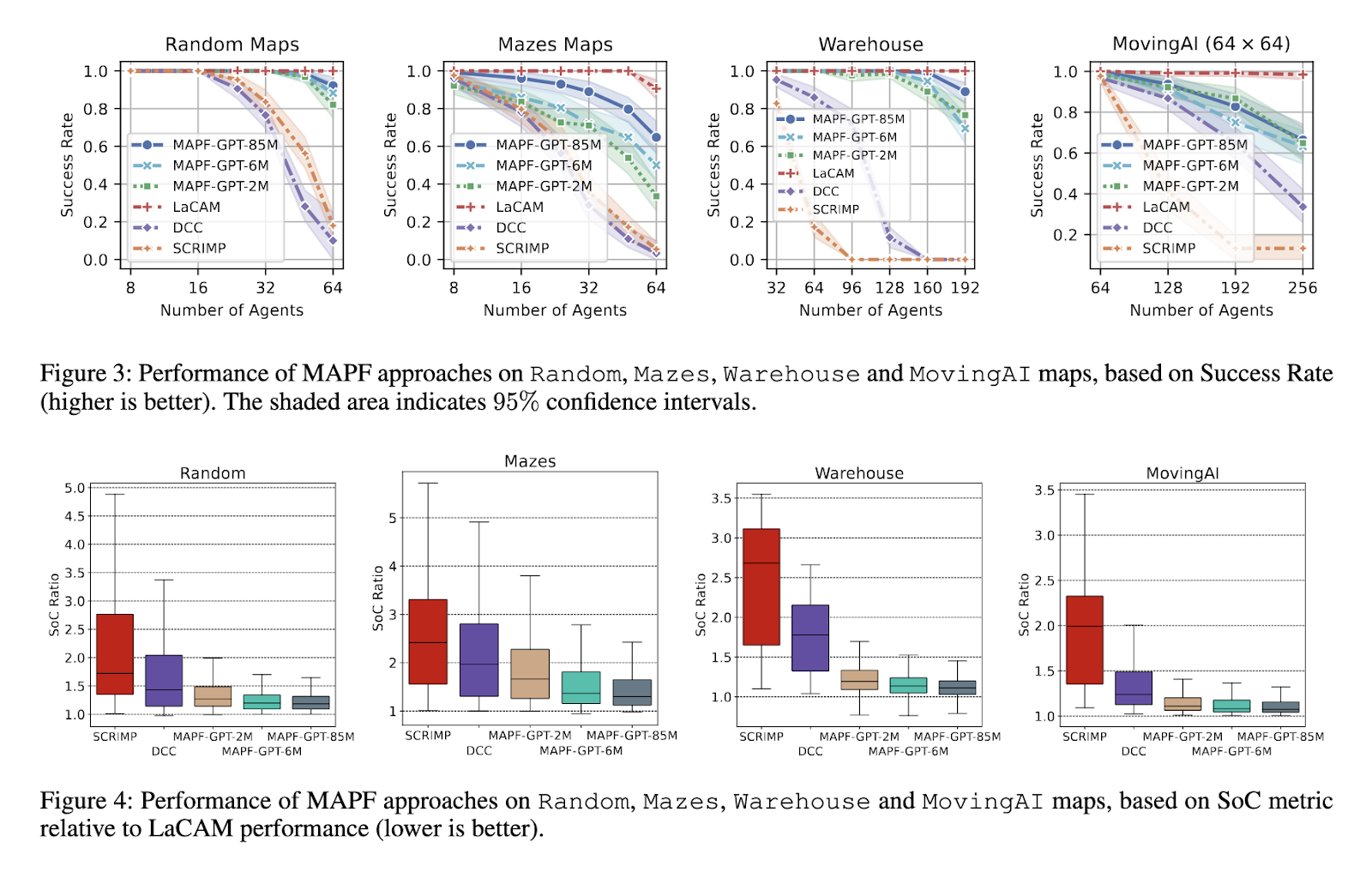
MAPF-GPT’s zero-shot learning capabilities were another remarkable achievement. The model solved MAPF problems it had not encountered during its training, demonstrating an ability to generalize to new environments. In a lifelong MAPF scenario, where agents receive new goals after reaching their initial ones, MAPF-GPT performed impressively without further training. The model outperformed traditional solvers like RHCR and learning-based models like FOLLOWER, particularly in warehouse simulations, where its decentralized nature allowed it to maintain high throughput.
Overall, the research introduced a promising new approach to solving the complex problem of multi-agent pathfinding. By relying on imitation learning and a transformer-based architecture, MAPF-GPT demonstrated significant advantages in speed, scalability, and generalization over existing methods. The model’s ability to operate without inter-agent communication or additional heuristics offers a streamlined solution for real-world applications, particularly in environments with large agents.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.



")


?: Top MLSecOps Tools (2025)")



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment