
")


Recent advancements in medical multimodal large language models (MLLMs) have shown significant progress in medical decision-making. However, many models, such as Med-Flamingo and LLaVA-Med, are designed for specific tasks and require large datasets and high computational resources, limiting their practicality in clinical settings. While the Mixture-of-Expert (MoE) strategy offers a solution using smaller, task-specific modules to reduce computational cost, its application in the medical domain remains underexplored. Lightweight yet effective models that handle diverse tasks and offer better scalability are essential for broader clinical utility in resource-constrained environments.
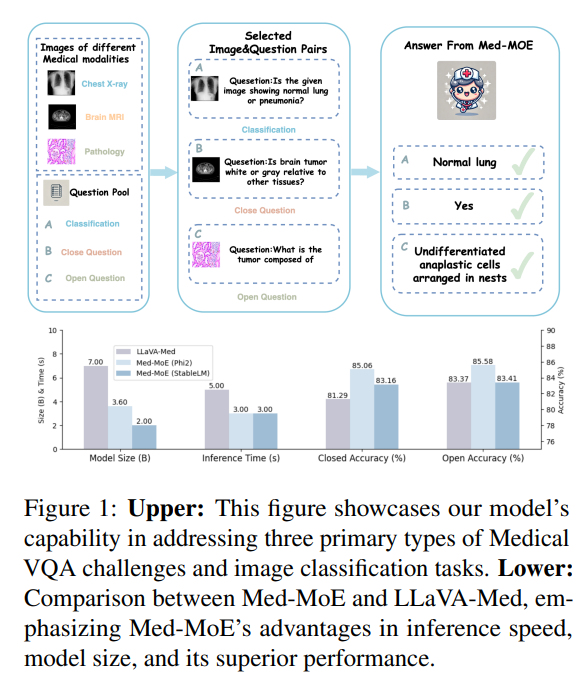
Researchers from Zhejiang University, the National University of Singapore, and Peking University introduced Med-MoE, a lightweight framework for multimodal medical tasks like Med-VQA and image classification. Med-MoE integrates domain-specific experts with a global meta-expert, emulating hospital workflows. The model aligns medical images and text, uses instruction tuning for multimodal tasks, and employs a router to activate relevant experts. Med-MoE outperforms or matches state-of-the-art models like LLaVA-Med with only 30%-50% of activated parameters. Tested on datasets like VQA-RAD and Path-VQA, it shows strong potential for improving medical decision-making in resource-constrained settings.
Advancements in MLLMs like Med-Flamingo, Med-PaLM M, and LLaVA-Med have significantly improved medical diagnostics by building on general AI models such as ChatGPT and GPT-4. These models enhance capabilities in few-shot learning and medical question answering but are often costly and underutilized in resource-limited settings. The MoE approach in MLLMs improves task handling and efficiency, either activating different experts for specific tasks or replacing standard layers with MoE structures. However, these methods often struggle with modal biases and lack effective specialization for diverse medical data.
The Med-MoE framework trains in three stages. First, in the Multimodal Medical Alignment phase, the model aligns medical images with textual descriptions using a vision encoder to produce image tokens and integrates them with text tokens to train a language model. Second, during Instruction Tuning and Routing, the model learns to handle medical tasks and generates responses while a router is trained to identify input modalities. Finally, in Domain-Specific MoE Tuning, the framework replaces the model’s feed-forward network with an MoE structure, where a meta-expert captures global information and domain-specific experts handle specific tasks, optimizing the model for precise medical decision-making.
The study evaluates Med-MoE models using various datasets and metrics, including accuracy and recall, with base models StableLM (1.7B) and Phi2 (2.7B). Med-MoE (Phi2) demonstrates superior performance over LLaVA-Med in VQA tasks and medical image classification, achieving 91.4% accuracy on PneumoniaMNIST. MoE-Tuning consistently outperforms traditional SFT, and integration with LoRA benefits GPU memory usage and inference speed. Simpler router architectures and specialized experts enhance model efficiency, with 2-4 activated experts effectively balancing performance and computation.
In conclusion, Med-MoE is a streamlined framework designed for multimodal medical tasks, optimizing performance in resource-limited settings by aligning medical images with language model tokens, task-specific tuning, and domain-specific fine-tuning. It achieves state-of-the-art results while reducing activated parameters. Despite its efficiency, Med-MoE encounters challenges such as limited medical training data due to privacy concerns and high costs of manual annotations. The model also struggles with complex, open-ended questions and must ensure trustworthy, explainable outputs in critical healthcare applications. Med-MoE offers a practical solution for advanced medical AI in constrained environments but needs improvements in data scalability and model reliability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.



")


?: Top MLSecOps Tools (2025)")



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment