



Large Language Models (LLMs) are primarily designed for text-based tasks, limiting their ability to interpret and generate multimodal content such as images, videos, and audio. Conventionally, multimodal operations are task-specific models trained on large amounts of labeled data, which makes them resource-hungry and rigid. Zero-shot methods are also restricted to pretraining with paired multimodal datasets, limiting their flexibility to new tasks. The challenge is to make LLMs perform multimodal reasoning and generation without task-specific training, curated data, or model adaptation. Overcoming this challenge would significantly enhance the applicability of LLMs to multimodal content processing and generation dynamically across multiple domains.
Conventional multimodal AI systems are based on models like CLIP for image-text alignment or diffusion models for media generation. Still, these methods are restricted to extensive training on curated data. Zero-shot captioning models like ZeroCap and MeaCap try to overcome this but are still restricted to fixed architectures and gradient-based optimization, restricting their generalization capability across different modalities. These methods have three limitations: they are restricted to extensive labeled data, they cannot generalize beyond the training distribution, and they are based on gradient-based methods that restrict their flexibility to new tasks. Without overcoming these limitations, multimodal AI is restricted to fixed tasks and datasets, restricting its potential for further applications.
Researchers from Meta propose MILS (Multimodal Iterative LLM Solver), a test-time optimization framework that enhances LLMs with multimodal reasoning capabilities without requiring additional training. Rather than adjusting the LLM or retraining it on multimodal data, MILS uses an iterative optimization cycle with a GENERATOR and a SCORER. The GENERATOR, an LLM, produces candidate solutions for multimodal tasks like image captions, video descriptions, or stylized image prompts, while the SCORER, a pre-trained multimodal model, ranks the generated solutions by relevance, coherence, and alignment with input data. Alternating between the two, MILS repeatedly refines its outputs with real-time feedback, continually improving performance. This enables zero-shot generalization across several modalities, including text, images, videos, and audio, making it an extremely versatile solution for multimodal AI applications.

MILS is implemented as a gradient-free optimization method, employing pre-trained models without tuning their parameters. The framework has been used in a variety of multimodal tasks. For image captioning, MILS employs Llama 3.1 8B as the GENERATOR and CLIP-based models as the SCORER to iteratively find optimal captions until the most accurate and descriptive caption is generated. The same iterative process is employed for video frames, with ViCLIP being used for evaluation, and for captioning audio, MILS extends the process to audio data with the use of ImageBind as the SCORER, allowing LLMs to generate natural language descriptions of sounds. For text-to-image generation, MILS optimizes image generation prompts by optimizing textual descriptions prior to sending them to diffusion-based models, generating more high-quality images. The framework even extends to style transfer, where it generates optimized editing prompts that direct style transfer models to generate more visually consistent transformations. In addition, it proposes cross-modal arithmetic, which combines heterogeneous modalities, such as an audio caption and an image description, into one multimodal representation. Using pre-trained models as scoring functions, MILS might avoid explicit multimodal training while being task-agnostic.
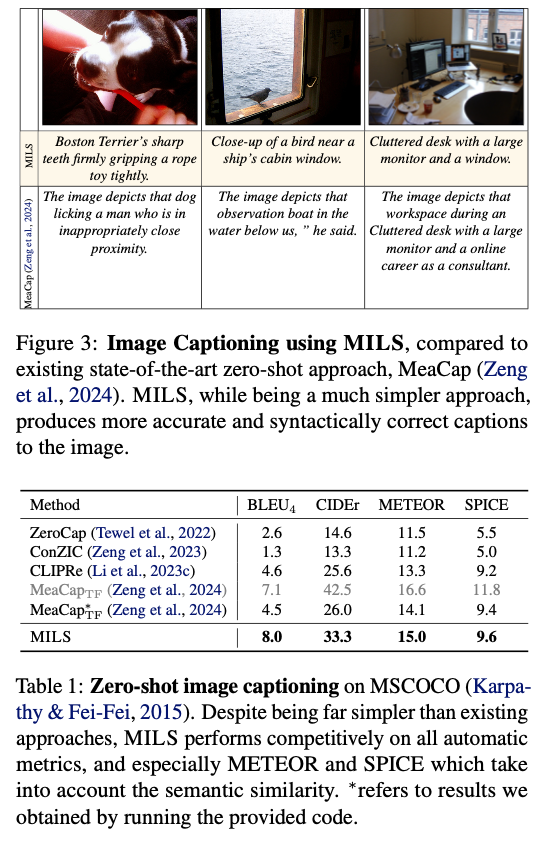

MILS achieves robust zero-shot performance on a variety of multimodal tasks and outperforms previous work on both captioning and generation. For image captioning, it is more semantically accurate than previous zero-shot models and generates more natural and informative captions. For captioning video and audio, it outperforms models trained on large-scale datasets even with zero task-specific training. For text-to-image generation, MILS improves image quality and fidelity, and human evaluators prefer its synthesized images in an overwhelming majority of cases. MILS is also effective for style transfer, learning optimal prompts for better visual transformation. Finally, MILS achieves new cross-modal arithmetic features, allowing combined information from modalities to generate coherent outputs. These findings demonstrate the flexibility and efficiency of MILS, making it a paradigm-breaking alternative to multimodal AI systems based on carefully curated training data.
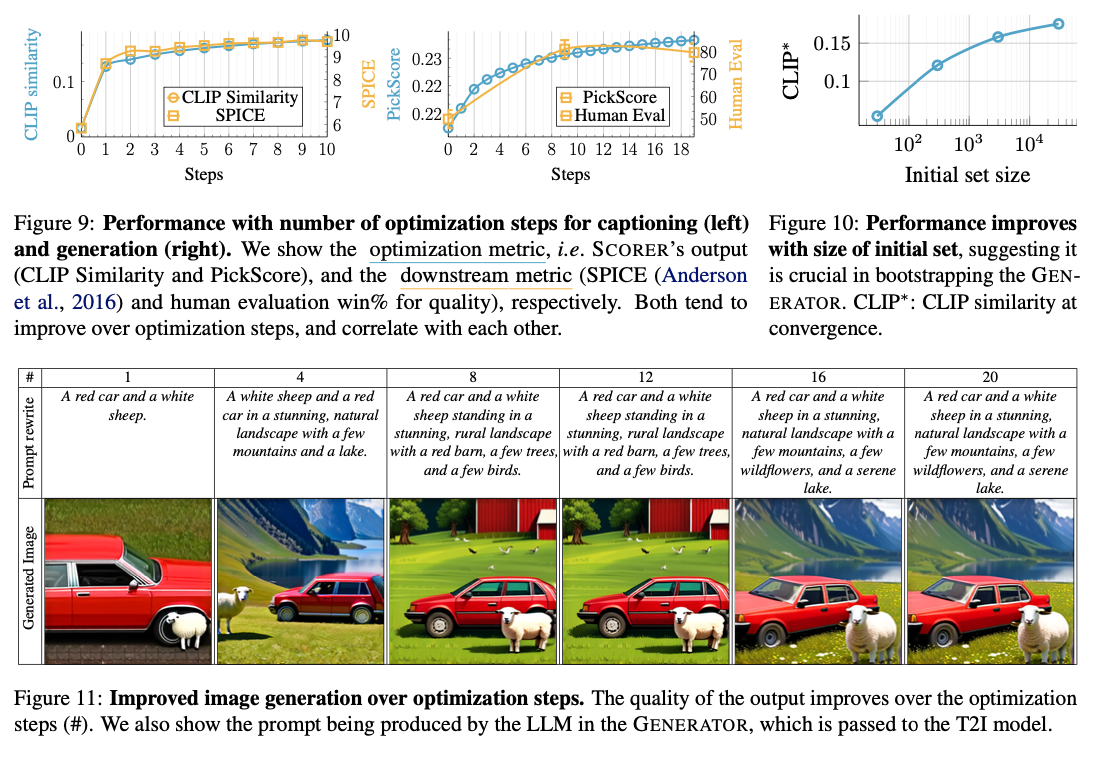
MILS offers a new paradigm for multimodal AI in its ability to let LLMs generate and process text, image, video, and audio content without training and fine-tuning. Its test-time iterative optimization mechanism allows emergent zero-shot generalization, outperforming previous zero-shot methods but staying simple. Using pre-trained LLMs and multimodal models in adaptive feedback, MILS creates a new state-of-the-art for multimodal AI, allowing for more adaptive and scalable AI systems that can dynamically process multimodal reasoning and generation tasks.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment