

 FAQs: Everything You Need to Know in 2025")
: A Breakthrough in LLM Performance")
The Mixture-of-Agents (MoA) architecture is a transformative approach for enhancing large language model (LLM) performance, especially on complex, open-ended tasks where a single model can struggle with accuracy, reasoning, or domain specificity.
How the Mixture-of-Agents Architecture Works
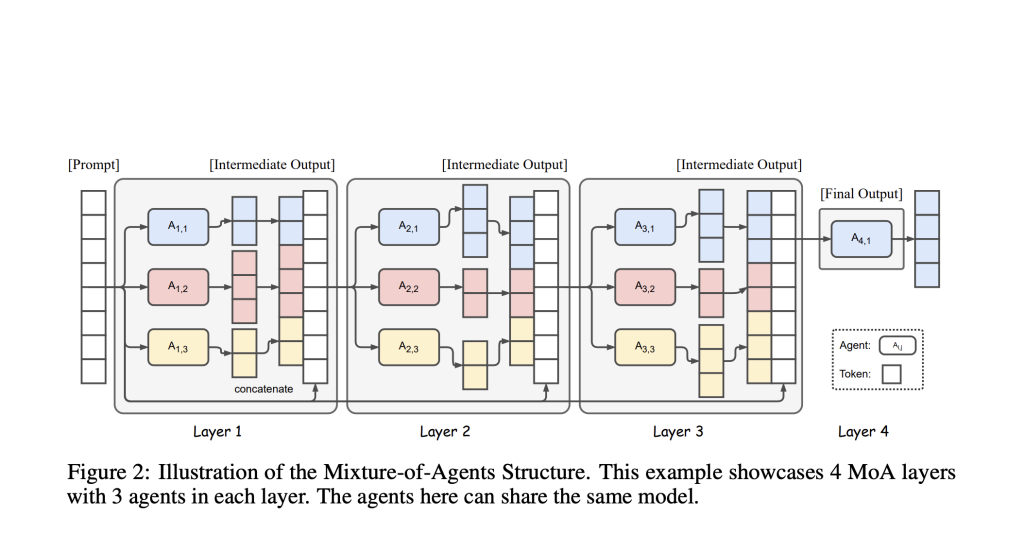
- Layered Structure: MoA frameworks organize multiple specialized LLM agents in layers. Each agent within a layer receives all outputs from agents in the previous layer as context for its own response—this promotes richer, more informed outputs.
- Agent Specialization: Each agent can be tailored or fine-tuned for specific domains or problem types (e.g., law, medicine, finance, coding), acting similarly to a team of experts, each contributing unique insights.
- Collaborative Information Synthesis: The process starts with a prompt being distributed among proposer agents who each offer possible answers. Their collective outputs are aggregated, refined, and synthesized by subsequent layers (with “aggregator” agents), gradually creating a single, comprehensive, high-quality result.
- Continuous Refinement: By passing responses across multiple layers, the system iteratively improves reasoning depth, consistency, and accuracy—analogous to human expert panels reviewing and enhancing a proposal.
Why Is MoA Superior to Single-Model LLMs?
- Higher Performance: MoA systems have recently outperformed leading single models (like GPT-4 Omni) on competitive LLM evaluation benchmarks, achieving, for example, 65.1% on AlpacaEval 2.0 versus GPT-4 Omni’s 57.5%—using only open-source LLMs.
- Better Handling of Complex, Multi-Step Tasks: Delegating subtasks to agents with domain-specific expertise enables nuanced, reliable responses even on intricate requests. This addresses key limitations of “jack-of-all-trades” models.
- Scalability and Adaptability: New agents can be added or existing ones retrained to address emerging needs, making the system more agile than retraining a monolithic model on every update.
- Error Reduction: By giving each agent a narrower focus and using an orchestrator to coordinate outputs, MoA architectures lower the likelihood of mistakes and misinterpretation—boosting both reliability and interpretability.
Real-World Analogy and Applications
Imagine a medical diagnosis: one agent specializes in radiology, another in genomics, a third in pharmaceutical treatments. Each reviews a patient’s case from its own angle. Their conclusions are integrated and weighted, with higher-level aggregators assembling the best treatment recommendation. This approach is now being adapted to AI for everything from scientific analysis to financial planning, law, and complex document generation.
Key Takeaways
- Collective Intelligence Over Monolithic AI: The MoA architecture leverages the collective strengths of specialized agents, producing results that surpass single, generalist models.
- SOTA Results and Open Research Frontier: The best MoA models are setting state-of-the-art results on industry benchmarks and are the focus of active research, pushing AI’s capability frontier forward.
- Transformative Potential: From critical enterprise applications to research assistants and domain-specific automation, the MoA trend is reshaping what is possible with AI agents.
In summary, combining specialized AI agents—each with domain-specific expertise—through MoA architectures leads to more reliable, nuanced, and accurate outputs than any single LLM, especially for sophisticated, multi-dimensional tasks.
Source:
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment