



There is no gainsaying that artificial intelligence has developed tremendously in various fields. However, the accurate evaluation of its progress would be incomplete without considering the generalizability and adaptability of AI models for specific domains. Domain Adaptation (DA) and Domain Generalization (DG) have garnered ample attention from researchers across the globe. Given that training is an exhaustive process and that the world has realized the scarcity of “good” data, it is imperative for models trained on limited source domains to perform well in novel areas.A considerable amount of research has been conducted in DA and DG. However, most of this research is based on unimodal data, such as images or time series. With the emergence of large-scale multimodal datasets, researchers are now striving to find a solution that addresses multimodal domain adaptation (MMDA) and generalization (MMDG) across multiple modalities, where the challenges become even more profound due to differences in characteristics. This article provides a comprehensive overview of the recent advances in MMDA and MMDG, from the traditional vanilla approaches to the use of foundation models and beyond.
Researchers from ETH, Zurich, and TUM, Germany, along with others, presented a comprehensive and exhaustive survey on advances in Multimodal Adaptation and Generalization. This survey covers the problem statement, challenges, datasets, applications, work done yet, and future directions for the following five topics in great detail:
(1) Multimodal domain adaptation -: The objective is to improve cross-domain knowledge transfer, i.e., train a model on a labeled source domain while ensuring it adapts effectively to an unlabeled target domain—despite distribution shifts. Researchers have struggled with the distinct characteristics of various modalities and ways to combine them. Furthermore, more often than not, inputs between modalities are missing.
To combat this issue, researchers have worked on various aspects, such as adversarial learning, contrastive learning, and cross-modal interaction techniques. Some significant works in this area are the MM-SADA and xMUDA frameworks.
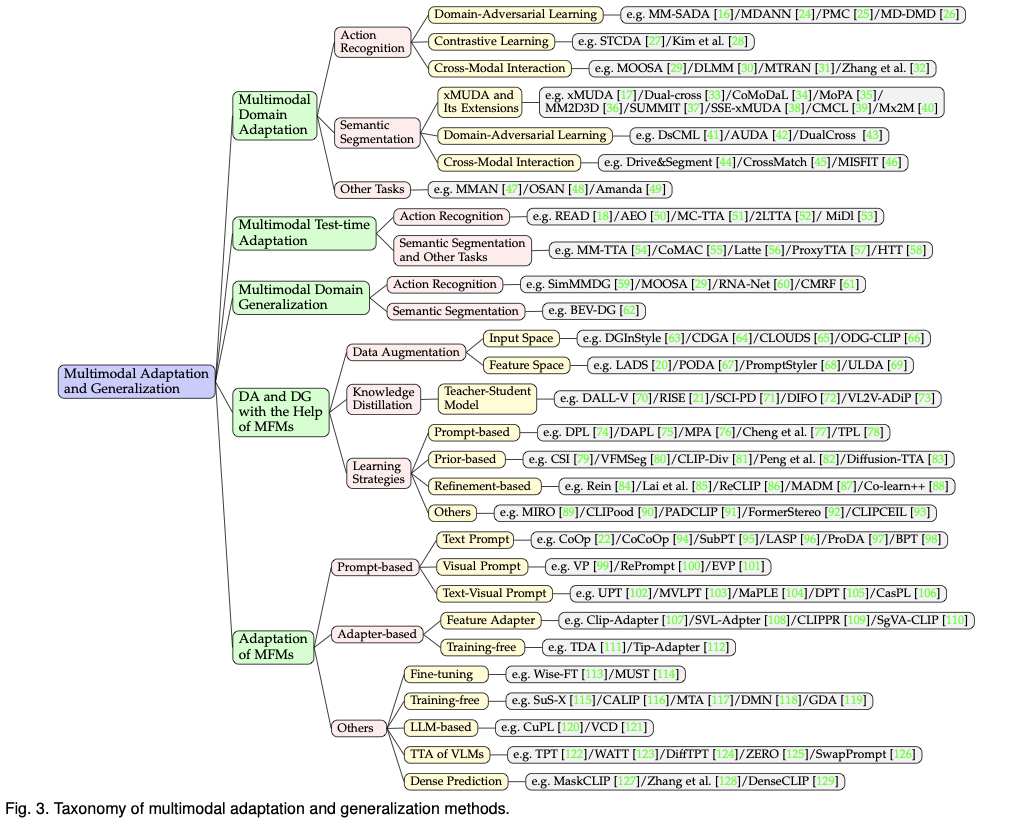
(2) Multimodal test-time adaptation- Unlike MMDA, which adapts models before deployment, Multimodal Test-Time Adaptation (MMTTA) focuses on the model’s ability to self-adjust dynamically during inference without needing labeled data. The major obstacle in this direction is the scarcity of source domain data. Additionally, continuous distribution shifts in data cannot work if the model requires retraining every time. Researchers have used self-supervised learning and uncertainty estimation techniques to solve this problem. Some notable contributions in this field are READ (Reliability-Aware Attention Distribution) and Adaptive Entropy Optimization (AEO).
(3) Multimodal domain generalization: Multimodal Domain Generalization (MMDG) aims to train AI models that can generalize to entirely new domains without prior exposure. Similar to the previous two, the absence of target domain data during training also creates problems in this objective. Moreover, the inconsistencies in feature distributions make it difficult for models to learn domain-invariant representations. This fieldwork has been done on Feature Disentanglement and Cross-Modal Knowledge Transfer with algorithms like SimMMDG, MOOSA, etc.
(4) Domain adaptation and generalization with the help of multimodal foundation models: This section mainly discusses the ascent of foundation models like CLIP in improving DA and DG. Foundation models are pre-trained and have a rich understanding of diverse modalities, which makes them suitable candidates. While these models seem the perfect solution to all the problems above, their usage remains challenging due to high computational demands and adaptability constraints. To combat this problem, researchers have proposed elegant methods like feature-space augmentation, knowledge distillation, and synthetic data generation through contributions such as CLIP-based feature augmentation and diffusion-driven synthetic data generation.
(5) Adaptation of multimodal foundation models: This subtopic deals with the issue of fine-tuning foundation models for adaptation purposes. Researchers have proposed techniques like Prompt-Based Learning and Adapter-Based Tuning to combat the computational expenses and dearth of domain data. Some recent and noteworthy works are CoOp and CoCoOp for the first and CLIP-Adapter and Tip-Adapter for the latter technique.
Conclusion: This article discussed the problem of generalizability and adaptability in multimodal applications. We saw numerous subdomains of this research area and various works, from naive augmentation approaches to foundation models that solve the challenges. Besides, this survey paper presented all the pertinent information and highlighted the future scope of work to develop more efficient, robust frameworks and self-learning models.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.






 and gpt-oss-20B (Runs on a Phone)")



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment