



Recent discussions on AI safety increasingly link it to existential risks posed by advanced AI, suggesting that addressing safety inherently involves considering catastrophic scenarios. However, this perspective has drawbacks: it may exclude researchers with different approaches, mislead the public into thinking AI safety is solely about existential threats, and create resistance among skeptics. As AI rapidly advances, policymakers must establish regulatory frameworks and safety standards. While existential risks dominate the current discourse, past technological safety fields—such as aviation, pharmaceuticals, and cybersecurity—have developed robust engineering and governance practices. These frameworks could inform AI safety, ensuring reliable and responsible system deployment.
Researchers from the University of Edinburgh and Carnegie Mellon University highlight that AI safety discussions often focus on existential risks, which may exclude diverse perspectives and mislead public perception. Their systematic review of peer-reviewed research reveals a broad spectrum of safety concerns, including adversarial robustness and interpretability, aligning with traditional system safety practices. The study suggests integrating near-term and long-term risks rather than prioritizing existential threats. While AI safety research evolves rapidly, capturing relevant studies remains challenging. Expanding discourse to incorporate established engineering safety principles can help address immediate and future AI risks effectively.
The researchers systematically reviewed AI safety literature using a structured methodology based on Kitchenham and Charters’ guidelines, complemented by snowball sampling to capture emerging research. They focused on two key research questions: identifying risks across the AI system lifecycle and evaluating proposed mitigation strategies. Their search process involved querying the Web of Science (WoS) and Scopus databases, refining results through hierarchical filters, and supplementing findings with influential seed papers. The review process included screening 2,666 database papers and 117 from snowball sampling, ultimately selecting 383 for analysis. Papers were annotated with metadata such as author affiliations, publication year, and citation count and were categorized based on methodological approaches, specific safety concerns addressed, and risk mitigation strategies.
The study’s bibliometric analysis revealed a steady increase in AI safety research since 2016, driven by advancements in deep learning. A word cloud analysis highlighted key themes such as safe reinforcement learning, adversarial robustness, and domain adaptation. A co-occurrence graph of abstract terms identified four major research clusters: (1) human and societal implications of AI, focusing on trust, accountability, and safety assurance; (2) safe reinforcement learning, emphasizing robust agent control in uncertain environments; (3) supervised learning, particularly in classification tasks, with a focus on robustness, generalization, and accuracy; and (4) adversarial attacks and defense strategies in deep learning models. The findings suggest that AI safety research aligns with traditional safety engineering principles, integrating aspects of reliability engineering, control theory, and cybersecurity to ensure AI systems are both effective and secure.
AI safety research categorizes risks into eight types: noise, lack of monitoring, system misspecification, and adversarial attacks. Most studies address issues related to noise and outliers, affecting model robustness and generalization. A significant focus is also on monitoring failures, system misspecifications, and control enforcement gaps. Research methods include applied algorithms, simulated agents, analysis frameworks, and mechanistic interpretability. While theoretical works propose conceptual models, applied studies develop practical algorithms. Recent efforts emphasize reinforcement learning safety, adversarial robustness, and explainability. The field parallels traditional engineering safety, integrating verification techniques to enhance AI reliability and mitigate potential risks.
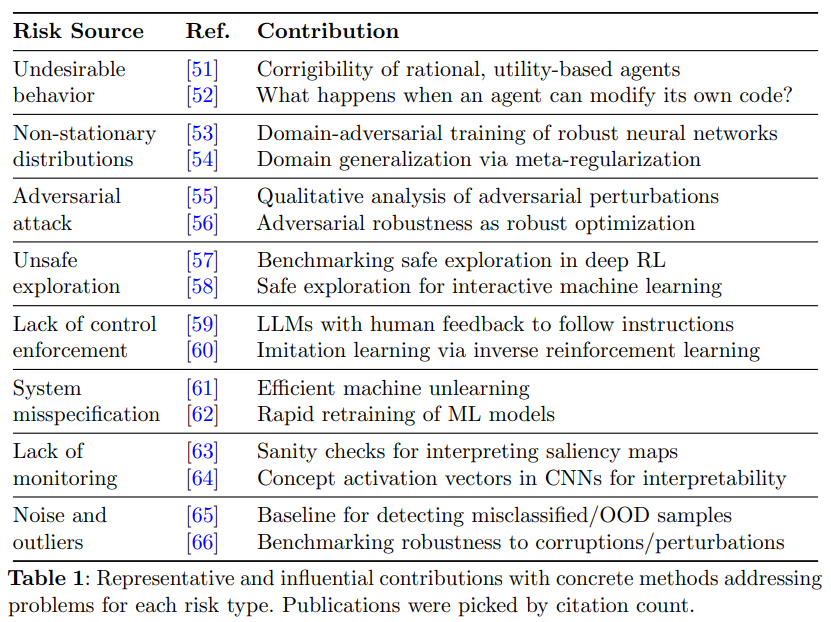
In conclusion, the study systematically reviewed peer-reviewed literature to explore AI safety challenges. The findings highlight diverse motivations and research outcomes aimed at ensuring AI systems are reliable and beneficial. AI safety research addresses various risks, including design flaws, robustness issues, inadequate monitoring, and embedded biases. The study advocates for framing AI safety within broader technological safety, expanding stakeholder engagement, and promoting inclusive research. While existential risks remain relevant, a wider perspective fosters productive discourse. Future research should explore sociotechnical AI safety and incorporate non-peer-reviewed sources for a comprehensive understanding, ensuring AI safety remains an evolving, inclusive, and multidisciplinary field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.





")

 and Reinforcement Fine-Tuning (RFT)")
")

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment