



Large language models (LLMs) have significantly advanced handling of complex tasks like mathematics, coding, and commonsense reasoning. However, improving the reasoning capabilities of these models remains a challenge. Researchers have traditionally focused on increasing the number of model parameters, but this approach has yet to hit a bottleneck, yielding diminishing returns and increasing computational costs. As a result, a growing need exists to explore more efficient ways to enhance reasoning without relying solely on scaling up models. The focus is shifting toward understanding and optimizing the patterns these models use to perform reasoning tasks.
A major problem facing LLM development is understanding how different models apply reasoning across tasks. More than simply increasing data and parameters is needed to solve the issue. Instead, researchers are interested in finding methods to analyze and enhance how models infer, interpret, and solve problems during real-time reasoning. Understanding these reasoning patterns can lead to better model optimization, where computational resources are used more effectively, enabling models to handle more complex tasks without unnecessary overhead.
Several tools and methods have been developed to study and compare the reasoning patterns of LLMs. These include “Test-time Compute” techniques such as Best-of-N (BoN), Step-wise BoN, Self-Refine, and Agent Workflow. These methods allow models to process multiple responses or break down large problems into smaller, manageable parts. However, while these methods help improve the model’s reasoning capabilities, they vary significantly in their effectiveness across different tasks, such as math and coding. This comparative analysis of the methods sheds light on their strengths and limitations when applied to various reasoning tasks.
Researchers from M-A-P, University of Manchester, OpenO1 Team, 2077AI, Abaka AI, Zhejiang University, and University of Chinese Academy of Sciences compared reasoning patterns using OpenAI’s o1 model as a benchmark. They tested the model on reasoning benchmarks in three critical areas: mathematics, coding, and commonsense reasoning. The benchmarks included datasets such as HotpotQA for commonsense reasoning, USACO for coding, and AIME for mathematics. The results demonstrated distinct reasoning patterns that set o1 apart from traditional methods, providing valuable insights into how LLMs process complex tasks.
The research revealed that the o1 model uses six primary reasoning patterns: Systematic Analysis (SA), Method Reuse (MR), Divide and Conquer (DC), Self-Refinement (SR), Context Identification (CI), and Emphasizing Constraints (EC). These patterns were observed to vary across different domains. For example, the model tended to rely heavily on Divide and Conquer (DC) and Method Reuse (MR) in math and coding tasks. In contrast, commonsense reasoning tasks frequently used Context Identification (CI) and Emphasizing Constraints (EC) more regularly. This variation suggests that the o1 model adapts its reasoning strategies depending on the nature of the problem at hand.
For mathematics, the researchers tested the model on the AIME benchmark, which contains complex problems requiring deep multi-step reasoning. The o1 model improved significantly over traditional methods, scoring 60% accuracy on the AIME24 dataset. Divide and Conquer allowed the model to break down mathematical problems into smaller components, solving each before arriving at a final answer. This approach contrasted with models like GPT-4o, which relied more heavily on scaling parameters but needed help with multi-step reasoning tasks that required a more structured approach.
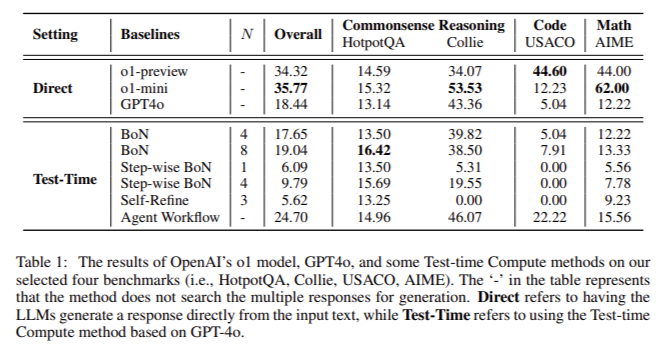
In coding tasks, the o1 model was evaluated using the USACO dataset, a benchmark that tests the model’s algorithmic and problem-solving skills. The o1 model’s performance surpassed traditional Test-time computing methods like Step-wise BoN and Self-Refine. The ability to use Method Reuse, where the model applied known solutions to similar problems, played a crucial role in its success. Additionally, the model’s ability to handle complex constraints and ensure accurate solutions through Self-Refinement was vital in these tasks.
In the HotpotQA dataset, which tests commonsense reasoning, the o1 model outperformed existing methods, achieving an accuracy of 35.77%, higher than BoN’s 34.32%. The o1 model’s ability to process multiple reasoning paths simultaneously and identify context-specific constraints helped it excel in this domain. Unlike in mathematical or coding tasks, where the model relied on structured problem-solving, commonsense reasoning required more flexibility, and the o1 model’s varied reasoning strategies allowed it to outperform others in this area.

Key Takeaways from the Research:
- The o1 model demonstrated six key reasoning patterns: Systematic Analysis (SA), Method Reuse (MR), Divide and Conquer (DC), Self-Refinement (SR), Context Identification (CI), and Emphasizing Constraints (EC).
- The model’s Divide and Conquer (DC) approach led to a 60% accuracy rate on the AIME24 mathematics benchmark, significantly outperforming other methods.
- In coding tasks using the USACO dataset, the o1 model excelled by leveraging Method Reuse (MR) and Self-Refinement (SR), achieving higher accuracy than traditional methods.
- The o1 model outperformed other models in the HotpotQA commonsense reasoning task, with a 35.77% accuracy, compared to 34.32% for BoN.
- The adaptability of the o1 model’s reasoning patterns allowed it to succeed across different domains, making it more effective than models relying solely on parameter scaling.

In conclusion, the study’s results highlight the importance of understanding the reasoning patterns used by LLMs. Traditional methods like BoN and Step-wise BoN were effective in certain contexts but fell short in tasks requiring multi-step reasoning or domain-specific prompts. The o1 model, by contrast, demonstrated an ability to adapt its reasoning patterns depending on the task, making it more versatile and effective in handling a wider range of problems.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment