



Large Language Models (LLMs) like GPT-4, Gemini, and Llama have revolutionized textual dataset augmentation, offering new possibilities for enhancing small downstream classifiers. However, this approach faces significant challenges. The primary issue lies in the substantial computational costs of LLM-based augmentation, resulting in high power consumption and CO2 emissions. Often featuring tens of billions of parameters, these models are significantly more resource-intensive than established augmentation methods such as back translation paraphrasing or BERT-based techniques. Researchers need help with the need to balance the improved performance of LLM-augmented classifiers against their environmental and economic costs. Also, conflicting results from existing studies have created uncertainty about the comparative effectiveness of LLM-based methods versus traditional approaches, highlighting the need for more comprehensive research in this area.
Researchers have explored various text augmentation techniques to enhance language model performance. Established methods include character-based augmentations, backtranslation, and earlier language models for paraphrasing. Advanced approaches incorporate style transfer, syntax control, and multilingual paraphrasing. With powerful LLMs like GPT-4 and Llama, augmentation techniques have been adapted to generate high-quality paraphrases. However, studies comparing LLM-based augmentation with established methods have yielded mixed results. Some research shows improved classifier accuracy with LLM paraphrasing, while others suggest it may not significantly outperform traditional techniques.
Researchers from Brno University of Technology, Kempelen Institute of Intelligent Technologies and the University of Pittsburgh compare established text augmentation methods with LLM-based approaches, focusing on accuracy and cost-benefit analysis. It investigates paraphrasing, word inserts, and word swaps in both traditional and LLM-based variants. The research uses six datasets across various classification tasks, three classifier models, and two fine-tuning approaches. By conducting 267,300 fine-tunings with varying sample sizes, the study aims to identify scenarios where traditional methods perform equally or better than LLM-based approaches and determine when the cost of LLM augmentation outweighs its benefits. This comprehensive analysis provides insights into optimal augmentation strategies for different use cases.

The study presents a meticulous comparison of established and LLM-based text augmentation methods through an extensive experimental design. It investigates three key augmentation techniques: paraphrasing, contextual word insertion, and word swap. These techniques are implemented using both traditional approaches, such as back translation and BERT-based contextual embeddings, and advanced LLM-based methods utilizing GPT-3.5 and Llama-3-8B. The research spans six diverse datasets, encompassing sentiment analysis, intent classification, and news categorization tasks, to ensure the broad applicability of findings. By employing three state-of-the-art classifier models (DistilBERT, RoBERTa, BERT) and two distinct fine-tuning approaches (full fine-tuning and QLoRA), the study provides a multifaceted examination of augmentation effects across various scenarios. This comprehensive design yields 37,125 augmented samples and an impressive 267,300 fine-tunings, enabling a robust and nuanced comparison of augmentation methodologies.
The evaluation process involves selecting seed samples, applying augmentation techniques, and fine-tuning classifiers using both original and augmented data. The study varies the number of seed samples and collected samples per seed to provide a nuanced understanding of augmentation effects. Manual validity checks ensure the quality of augmented samples. Multiple fine-tuning runs with different random seeds enhance result reliability. This extensive approach allows for a comprehensive analysis of the augmentation method’s accuracy and cost-effectiveness, addressing the study’s primary research questions on the comparative performance and cost-benefit analysis of established versus LLM-based augmentation techniques.
The study compared LLM-based and established text augmentation methods across various parameters, revealing subtle results. LLM-based paraphrasing outperformed other LLM methods in 56% of cases, while contextual word insert led among established methods with the same percentage. For full fine-tuning, LLM-based paraphrasing consistently surpassed contextual insert. However, QLoRA fine-tuning showed mixed results, with contextual insert often outperforming LLM-based paraphrasing for RoBERTa. LLM methods demonstrated higher effectiveness with fewer seed samples (5-20 per label), showing a 3% to 17% accuracy increase for QLoRA and 2% to 11% for full fine-tuning. As the number of seeds increased, the performance gap between LLM and established methods narrowed. Notably, RoBERTa achieved the highest accuracy across all datasets, suggesting that cheaper established methods can be competitive with LLM-based augmentation for high-performing classifiers, except when using a small number of seeds.


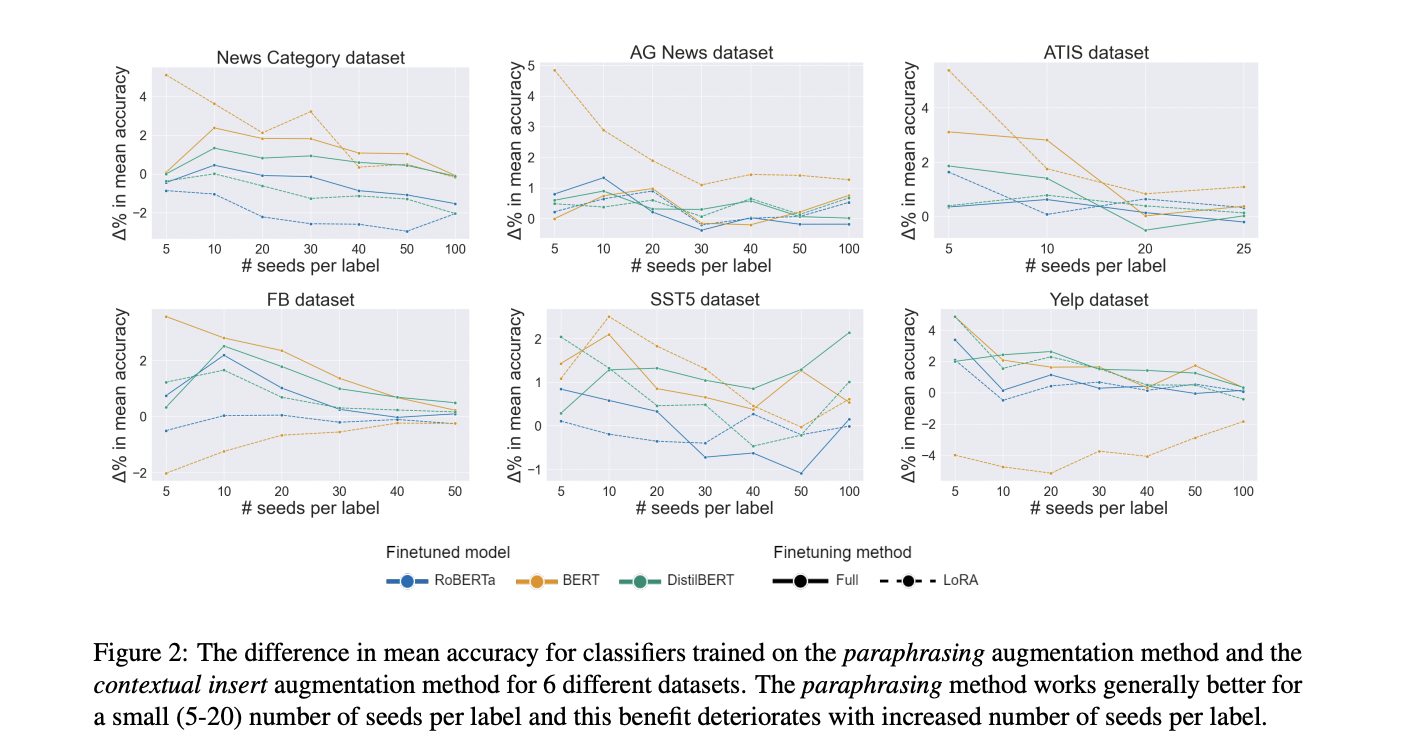
The study conducted an extensive comparison between newer LLM-based and established textual augmentation methods, analyzing their impact on downstream classifier accuracy. The research encompassed 6 datasets, 3 classifiers, 2 fine-tuning approaches, 2 augmenting LLMs, and various numbers of seed samples per label and augmented samples per seed, resulting in 267,300 fine-tunings. Among the LLM-based methods, paraphrasing emerged as the top performer, while contextual insert led the established methods. Results indicate that LLM-based methods are primarily beneficial in low-resource settings, specifically with 5 to 20 seed samples per label, where they showed statistically significant improvements and higher relative increases in model accuracy compared to established methods. However, as the number of seed samples increased, this advantage diminished, and established methods began to show superior performance more frequently. Given the considerably higher costs associated with newer LLM methods, their use is justified only in low-resource scenarios where the cost difference is less pronounced.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.









: A Family of Universal Models for Atoms")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment