



The 3D occupancy prediction methods faced challenges in depth estimation, computational efficiency, and temporal information integration. Monocular vision struggled with depth ambiguities, while stereo vision required extensive calibration. Temporal fusion approaches, including attention-based, WrapConcat-based, and plane-sweep-based methods, attempted to address these issues but often lacked robust temporal geometry understanding. Many techniques implicitly leveraged temporal information, limiting their ability to fully exploit 3D geometric constraints. Long temporal fusion methods, such as BEVFormer, struggled to effectively utilize distant historical frames due to recurrent fusion processes. These limitations prompted the development of CVT-Occ to enhance prediction accuracy while minimizing computational costs.

Researchers from Tsinghua University, Shanghai AI Lab, and UC Berkeley have developed CVT-Occ, a novel approach for 3D occupancy prediction addressing challenges in monocular vision systems. The method leverages temporal fusion through geometric correspondence of voxels over time, sampling points along the line of sight and integrating features from historical frames. This technique constructs a cost volume feature map to refine current volume features, enhancing prediction accuracy. Validated on the Occ3D-Waymo dataset, CVT-Occ outperforms existing state-of-the-art methods while maintaining minimal computational costs. The research addresses limitations in depth estimation and stereo vision calibration, offering a promising solution for improved 3D occupancy prediction in various applications.
CVT-Occ methodology enhances 3D occupancy prediction through temporal fusion and geometric correspondences. The approach constructs a cost volume feature map by sampling points along the line of sight and integrating historical frame features. Geometric correspondences across temporal frames leverage the parallax effect to improve depth estimation accuracy. A projection matrix transforms points between ego-vehicle and global coordinate frames, enabling the extraction of complementary information from past observations. The method mitigates depth ambiguity by utilizing historical BEV features and projecting points into the historical coordinate frame.
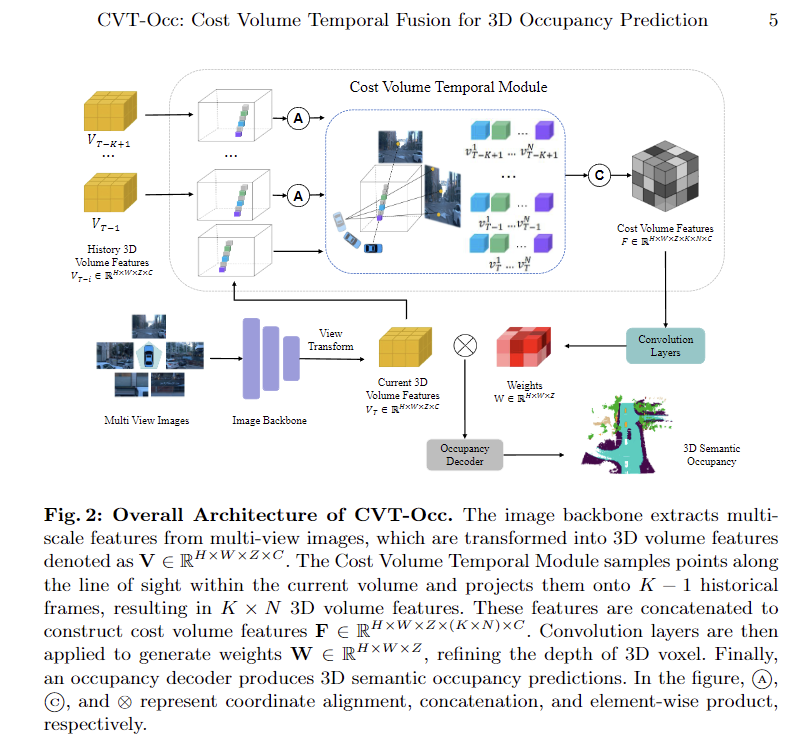
Experimental validation on the Occ3D-Waymo dataset demonstrates CVT-Occ’s superior performance over existing state-of-the-art methods while maintaining low computational overhead. The approach integrates with existing models by replacing original decoders with a 3D occupancy prediction decoder, ensuring effective utilization of the cost volume feature map. This methodology significantly improves predictions on object geometry and occupancy accuracy through its innovative use of temporal fusion, cost volume construction, and historical feature integration, making it a robust solution for 3D occupancy prediction tasks.
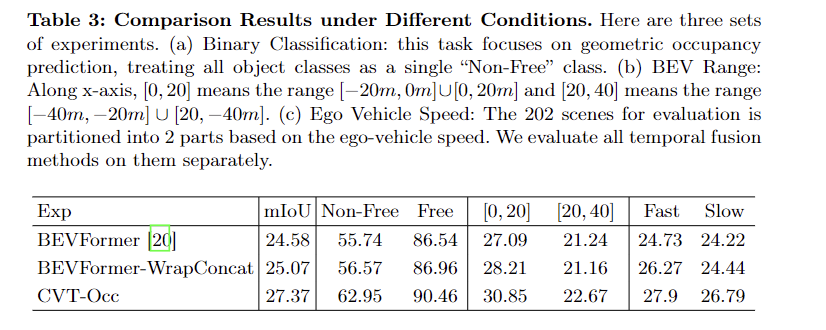
Results from CVT-Occ demonstrate a 2.8% mIoU improvement over BEVFormer in 3D occupancy prediction. The method excels in fast-moving scenarios, with +3.17 mIoU gains versus +2.57 in slow conditions. Performance improvements exceed 4% for various object classes. Ablation studies highlight the importance of longer time spans and effective temporal fusion. CVT-Occ integrates information from all historical frames, overcoming the limitations of previous methods. It outperforms mainstream temporal fusion approaches, setting a new benchmark. The method’s success stems from comprehensive temporal geometry understanding and effective parallax effect utilization while maintaining low computational overhead.
In conclusion, CVT-Occ significantly enhances 3D occupancy prediction accuracy through effective temporal fusion and geometric correspondence. The innovative cost volume feature map, integrating historical frame data, proves crucial for superior performance. The method’s long temporal fusion capabilities and parallax utilization are key to its success. CVT-Occ opens new research avenues in 3D perception, with potential applications in reconstruction, robotics, and virtual reality. The approach demonstrates the importance of leveraging entire temporal sequences and integrating supplementary supervision for improved scene understanding, marking a substantial advancement in the field.
Check out the Page and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI





: Build a Weather Agent with Python")




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment