



Large Language Models (LLMs) have become integral to numerous AI systems, showcasing remarkable capabilities in various applications. However, as the demand for processing long-context inputs grows, researchers face significant challenges in optimizing LLM performance. The ability to handle extensive input sequences is crucial for enhancing AI agents’ functionality and improving retrieval augmented generation techniques. While recent advancements have expanded LLMs’ capacity to process inputs of up to 1M tokens, this comes at a substantial cost in computational resources and time. The primary challenge lies in accelerating LLM generation speed and reducing GPU memory consumption for long-context inputs, which is essential for minimizing response latency and increasing throughput in LLM API calls. Although techniques like KV cache optimization have improved the iterative generation phase, the prompt computation phase remains a significant bottleneck, especially as input contexts lengthen. This prompts the critical question: How can researchers accelerate speed and reduce memory usage during the prompt computation phase?
Prior attempts to accelerate LLM generation speed with long context inputs have primarily focused on KV cache compression and eviction techniques. Methods like selective eviction of long-range contexts, streaming LLM with attention sinks, and dynamic sparse indexing have been developed to optimize the iterative generation phase. These approaches aim to reduce memory consumption and running time associated with the KV cache, especially for lengthy inputs.
Some techniques, such as QuickLLaMA and ThinK, classify and prune the KV cache to preserve only essential tokens or dimensions. Others, like H2O and SnapKV, focus on retaining tokens that contribute significantly to cumulative attention or are essential based on observation windows. While these methods have shown promise in optimizing the iterative generation phase, they do not address the bottleneck in the prompt computation phase.
A different approach involves compressing input sequences by pruning redundancy in the context. However, this method requires retaining a substantial portion of input tokens to maintain LLM performance, limiting its effectiveness for significant compression. Despite these advancements, the challenge of simultaneously reducing running time and GPU memory usage during both the prompt computation and iterative generation phases remains largely unaddressed.
Researchers from University of Wisconsin-Madison, Salesforce AI Research, and The University of Hong Kong present GemFilter, a unique insight into how LLMs process information. This approach is based on the observation that LLMs often identify relevant tokens in the early layers, even before generating an answer. GemFilter utilizes these early layers, referred to as “filter layers,” to compress long input sequences significantly.
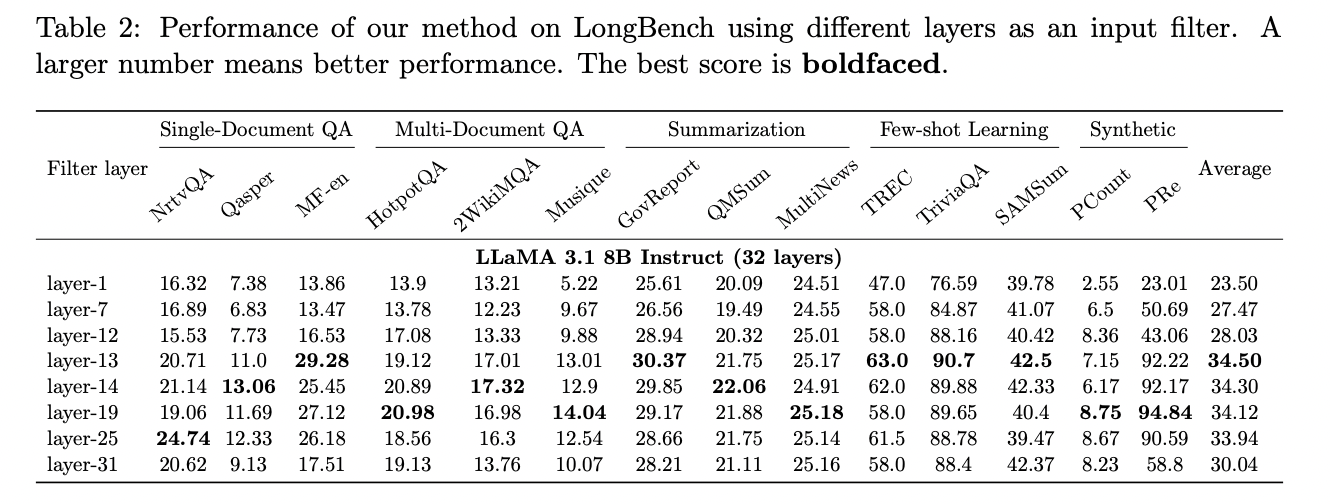
The method works by analyzing the attention matrix from these early layers to distil the necessary information for answering queries. For instance, in the LLaMA 3.1 8B model, the 13th to 19th layers can effectively summarize the required information. This allows GemFilter to perform prompt computation on long context inputs only for these filter layers, compressing the input tokens from as many as 128K to just 100.
By selecting a subset of tokens based on the attention patterns in these early layers, GemFilter achieves substantial reductions in both processing time and GPU memory usage. The selected tokens are then fed into the full model for inference, followed by standard generation functions. This approach addresses the bottleneck in the prompt computation phase while maintaining performance comparable to existing methods in the iterative generation phase.
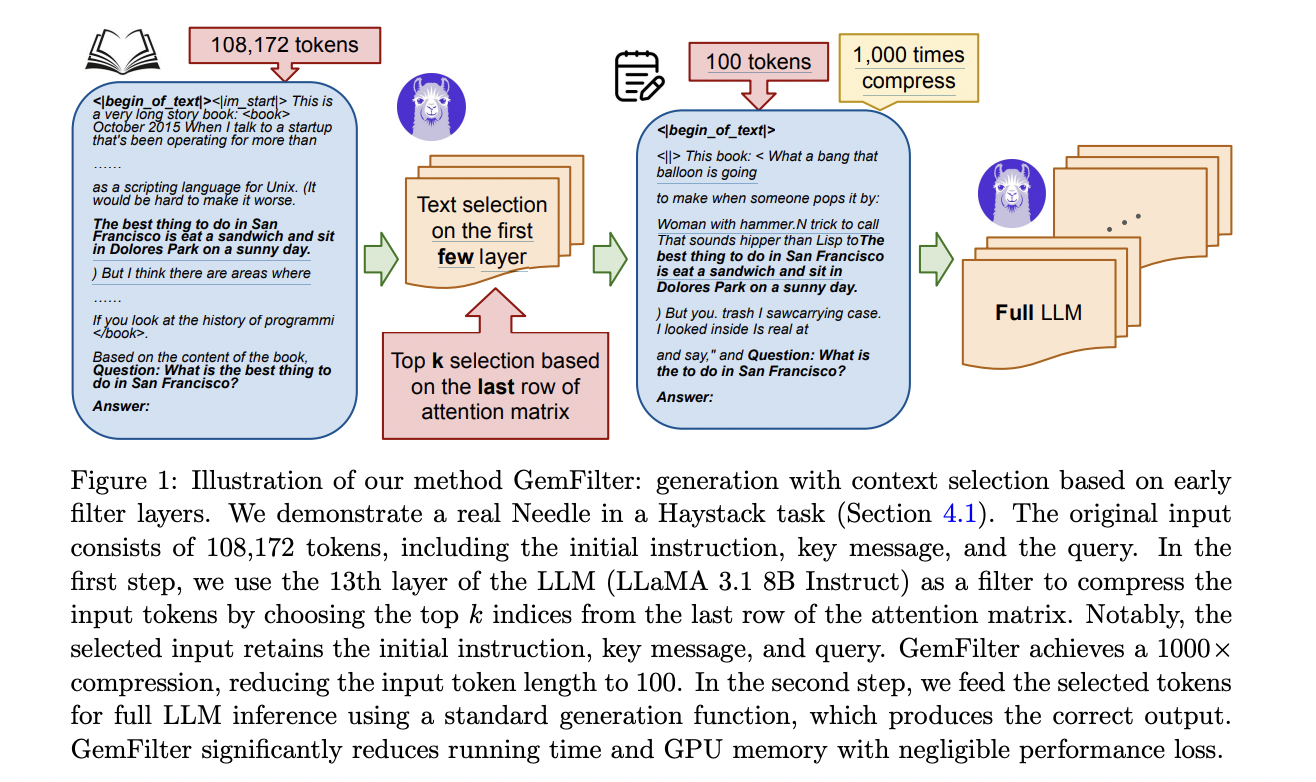
GemFilter’s architecture is designed to optimize LLM performance by leveraging early layer processing for efficient token selection. The method utilizes the attention matrices from early layers, specifically the “filter layers,” to identify and compress relevant input tokens. This process involves analyzing the attention patterns to select a small subset of tokens that contain the essential information needed for the task.
The core of GemFilter’s architecture is its two-step approach:
1. Token Selection: GemFilter uses the attention matrix from an early layer (e.g., the 13th layer in LLaMA 3.1 8B) to compress the input tokens. It selects the top k indices from the last row of the attention matrix, effectively reducing the input size from potentially 128K tokens to around 100 tokens.
2. Full Model Inference: The selected tokens are then processed through the entire LLM for full inference, followed by standard generation functions.
This architecture allows GemFilter to achieve significant speedups and memory reductions during the prompt computation phase while maintaining performance in the iterative generation phase. The method is formulated in Algorithm 1, which outlines the specific steps for token selection and processing. GemFilter’s design is notable for its simplicity, lack of training requirements, and broad applicability across various LLM architectures, making it a versatile solution for improving LLM efficiency.
GemFilter’s architecture is built around a two-pass approach to optimize LLM performance. The core algorithm, detailed in Algorithm 1, consists of the following key steps:
1. Initial Forward Pass: The algorithm runs only the first r layers of the m-layer transformer network on the input sequence T. This step generates the query and key matrices (Q(r) and K(r)) for the r-th layer, which serves as the filter layer.
2. Token Selection: Using the attention matrix from the r-th layer, GemFilter selects the k most relevant tokens. This is done by identifying the k largest values from the last row of the attention matrix, representing the interaction between the last query token and all key tokens.
3. Multi-Head Attention Handling: For multi-head attention, the selection process considers the summation of the last row across all attention heads’ matrices.
4. Token Reordering: The selected tokens are then sorted to maintain their original input order, ensuring proper sequence structure (e.g., keeping the <bos> token at the beginning).
5. Final Generation: The algorithm runs a full forward pass and generation function using only the selected k tokens, significantly reducing the input context length (e.g., from 128K to 1024 tokens).
This approach allows GemFilter to efficiently process long inputs by leveraging early layer information for token selection, thereby reducing computation time and memory usage in both the prompt computation and iterative generation phases.

GemFilter demonstrates impressive performance across multiple benchmarks, showcasing its effectiveness in handling long-context inputs for LLMs.
In the Needle in a Haystack benchmark, which tests LLMs’ ability to retrieve specific information from extensive documents, GemFilter significantly outperforms both standard attention (All KV) and SnapKV methods. This superior performance is observed for both Mistral Nemo 12B Instruct and LLaMA 3.1 8B Instruct models, with input lengths of 60K and 120K tokens respectively.
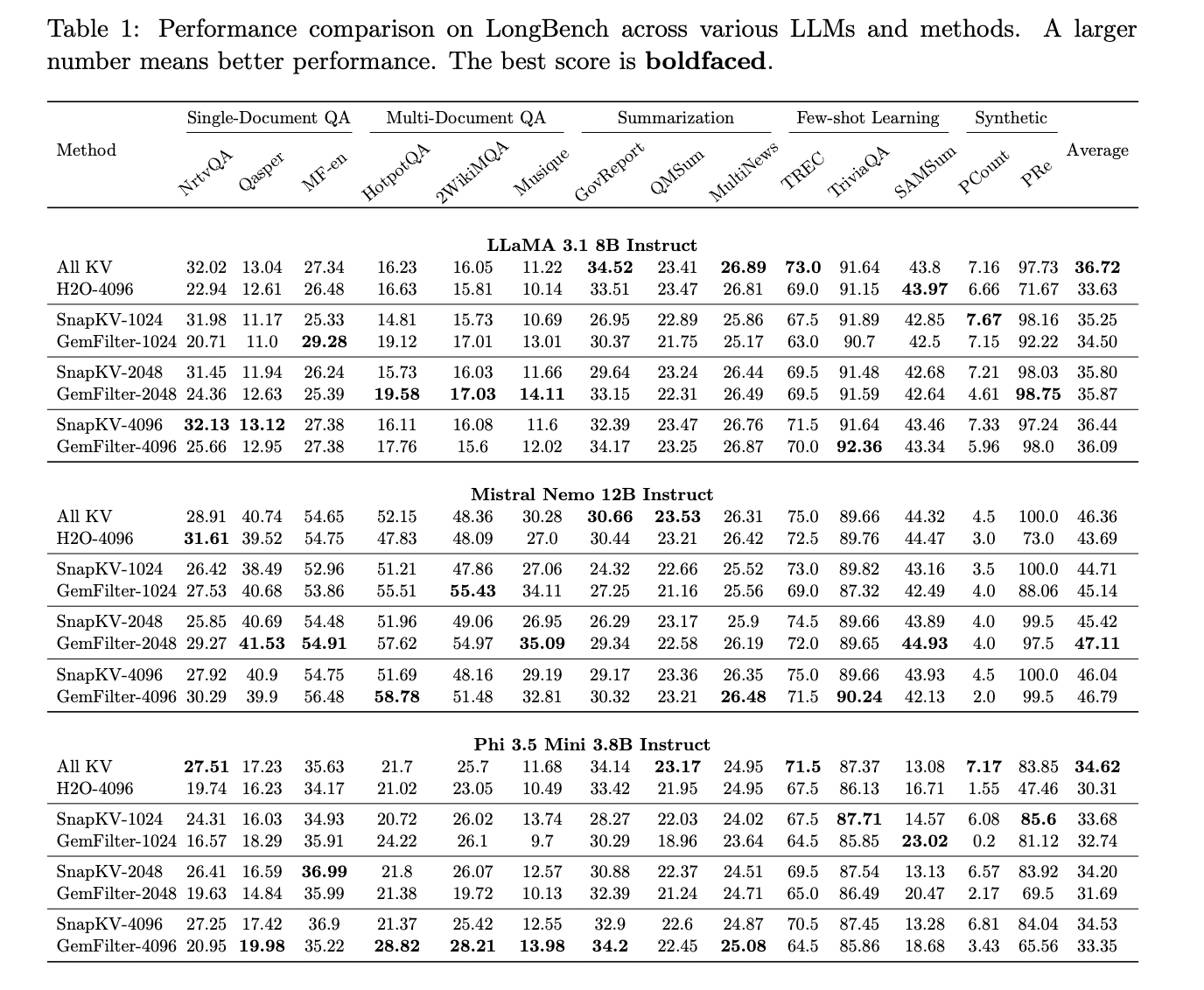
On the LongBench multi-task benchmark, which evaluates long-context understanding across various tasks, GemFilter shows comparable or better performance to standard attention, even when using only 1024 selected tokens. For instance, GemFilter-2048 outperforms standard attention for the Mistral Nemo 12B Instruct model. GemFilter also demonstrates significantly better performance than H2O and comparable performance to SnapKV.
Notably, GemFilter achieves these results while effectively compressing input contexts. It reduces input tokens to an average of 8% when using 1024 tokens, and 32% when using 4096 tokens, with negligible accuracy drops. This compression capability, combined with its ability to filter key information and provide interpretable summaries, makes GemFilter a powerful tool for optimizing LLM performance on long-context tasks.
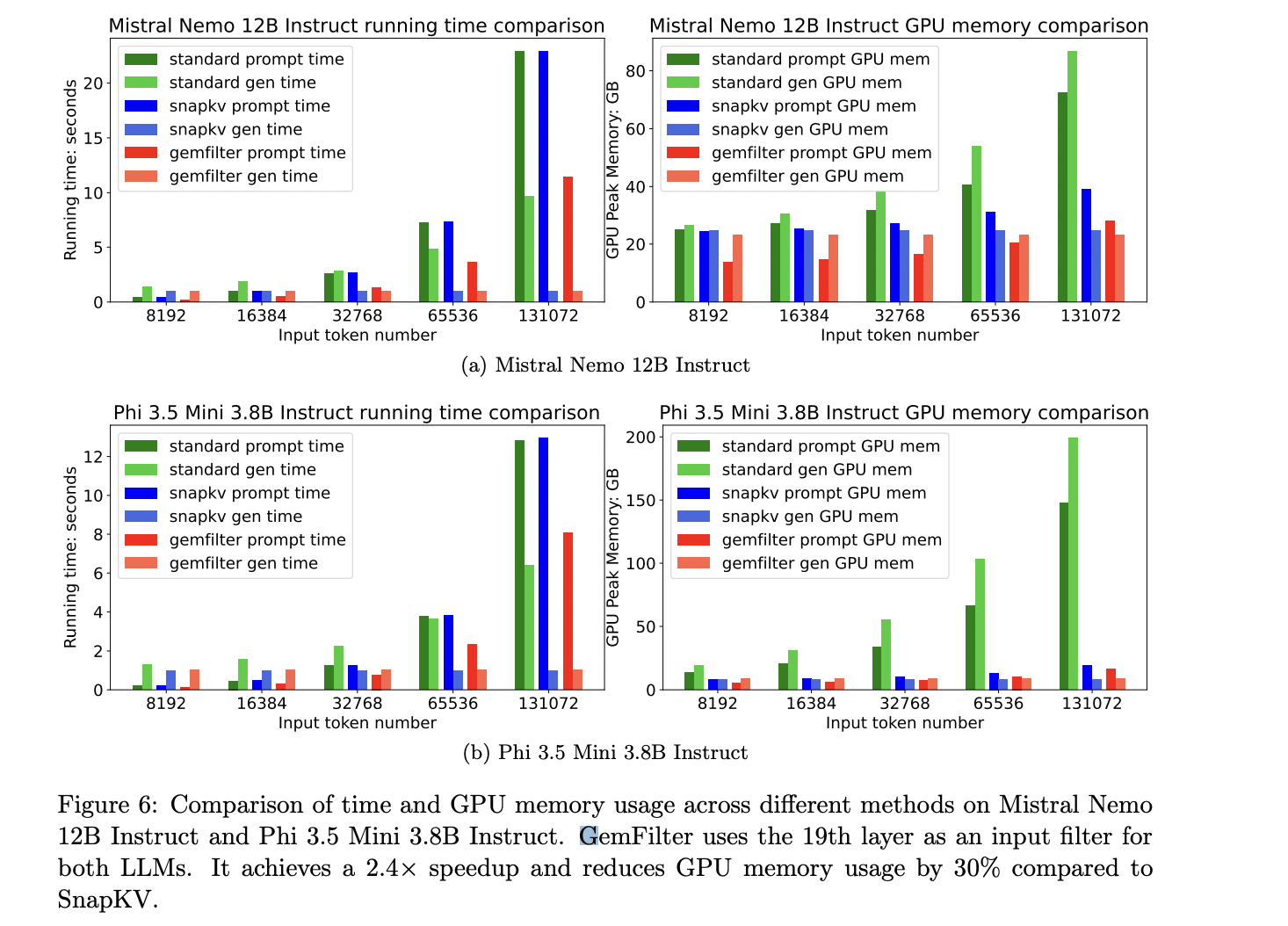
GemFilter demonstrates significant improvements in computational efficiency and resource utilization. Compared to existing approaches like SnapKV and standard attention, GemFilter achieves a 2.4× speedup while reducing GPU memory usage by 30% and 70%, respectively. This efficiency gain stems from GemFilter’s unique three-stage processing approach, where the long input context is handled only during the initial stage. Subsequent stages operate on compressed inputs, leading to substantial resource savings. Experiments with Mistral Nemo 12B Instruct and Phi 3.5 Mini 3.8B Instruct models further confirm GemFilter’s superior performance in terms of running time and GPU memory consumption compared to state-of-the-art methods.
This study presents GemFilter, a robust approach to enhance LLM inference for long context inputs, addressing critical challenges in speed and memory efficiency. By harnessing the capabilities of early LLM layers to identify relevant information, GemFilter achieves remarkable improvements over existing techniques. The method’s 2.4× speedup and 30% reduction in GPU memory usage, coupled with its superior performance on the Needle in a Haystack benchmark, underscore its effectiveness. GemFilter’s simplicity, training-free nature, and broad applicability to various LLMs make it a versatile solution. Moreover, its enhanced interpretability through direct token inspection offers valuable insights into LLM internal mechanisms, contributing to both practical advancements in LLM deployment and deeper understanding of these complex models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.







 Framework that Enables Partially Unmasked Tokens during Sampling")


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment