



Large Language Models (LLMs) have become increasingly important in cybersecurity, particularly in their application to secure coding practices. As these AI-driven models can generate human-like text, they are now being utilized to detect and mitigate security vulnerabilities in software. The primary goal is to harness these models to enhance the security of code, which is essential in preventing potential cyberattacks and ensuring the integrity of software systems. The integration of AI in cybersecurity represents a significant advancement in automating the identification and resolution of code vulnerabilities, which has traditionally relied on manual processes.
A pressing problem in cybersecurity is the persistent presence of vulnerabilities in software code that malicious actors can exploit. These vulnerabilities often arise from simple coding errors or overlooked security flaws during software development. Traditional methods, such as manual code reviews and static analysis, are only sometimes effective in catching all possible vulnerabilities, especially as software systems grow increasingly complex. The challenge lies in developing automated solutions that can accurately identify and fix these issues before they are exploited, thereby enhancing the overall security of the software.
Current tools for secure coding include static analyzers like CodeQL and Bandit, which are widely used in the industry to scan codebases for known security vulnerabilities. These tools work by analyzing the code without executing it and identifying potential security flaws based on predefined patterns and rules. However, while these tools effectively detect common vulnerabilities, they are limited by their reliance on predefined rules, which may not account for new or complex security threats. Furthermore, Automated Program Repair (APR) tools have been developed to fix bugs in code automatically. However, these tools typically focus on simpler issues and often fail to address more complex vulnerabilities, leaving gaps in the security of the code.
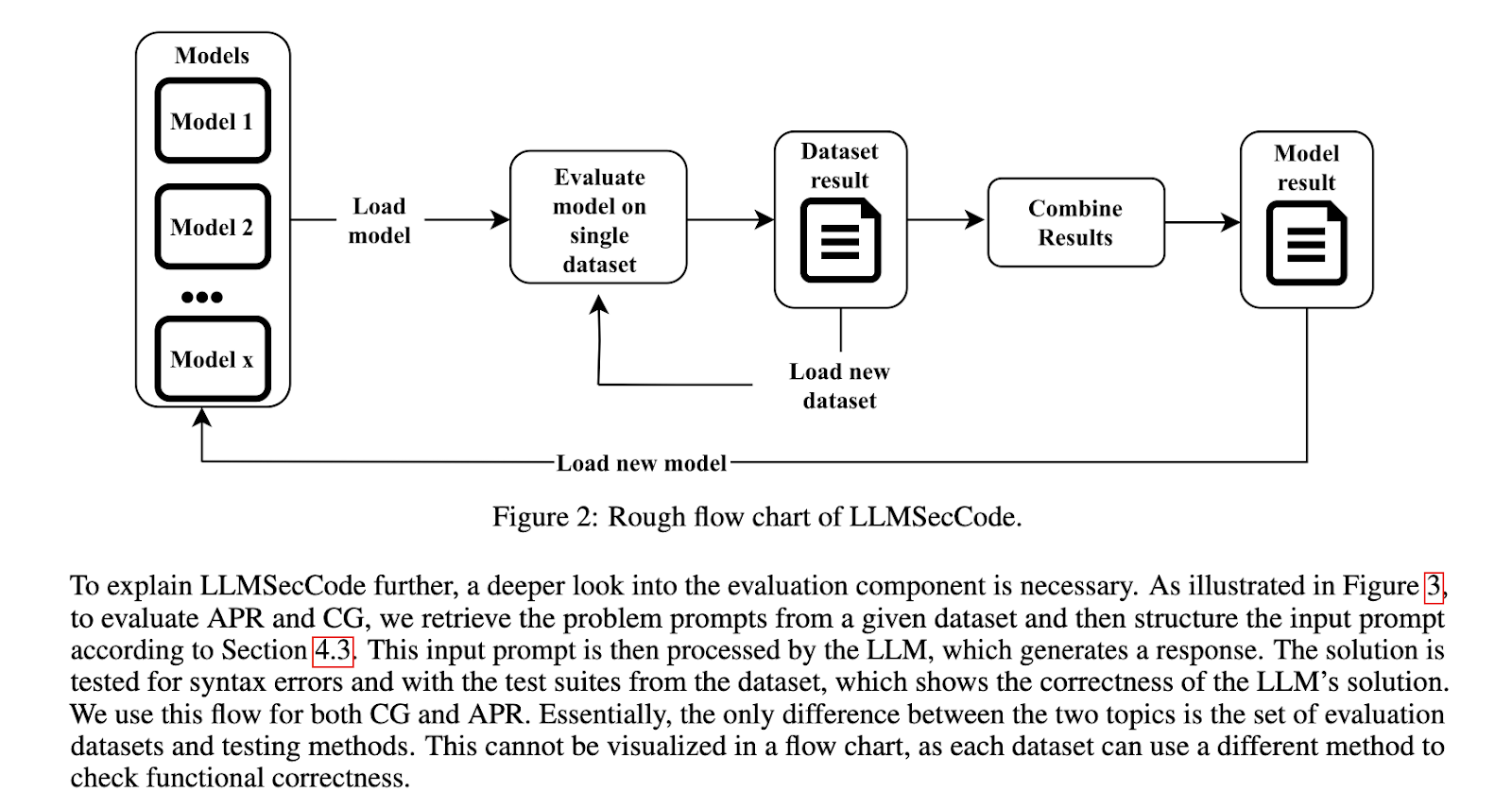
Researchers from Chalmers University of Technology in Sweden have introduced LLMSecCode, an innovative open-source framework designed to evaluate the secure coding capabilities of LLMs. This framework represents a significant step forward in the standardization and benchmarking LLMs for secure coding tasks. LLMSecCode provides a comprehensive platform for assessing how well different LLMs can generate secure code and repair vulnerabilities. By integrating this framework, researchers aim to streamline the process of evaluating LLMs, making it easier to determine which models are most effective for secure coding. The framework’s open-source nature also encourages further development and collaboration within the research community.
The LLMSecCode framework operates by varying key parameters of LLMs, such as temperature and top-p, which are crucial in determining the model’s output. By adjusting these parameters, researchers can observe how changes affect the LLM’s ability to generate secure code and identify vulnerabilities. The framework supports multiple LLMs, including CodeLlama and DeepSeekCoder, among the current state-of-the-art models in secure coding. LLMSecCode also allows for the customization of prompts, enabling researchers to tailor the tasks to specific needs. This customization is essential in evaluating the model’s performance across secure coding scenarios. The framework is designed to be adaptable & scalable, making it suitable for various secure coding tasks.


The performance of LLMSecCode was rigorously tested using various LLMs, yielding significant insights into their capabilities. The researchers found that DeepSeek Coder 33B Instruct achieved remarkable success in Automated Program Repair (APR) tasks, solving up to 78.7% of the challenges it was presented with. In contrast, Llama 2 7B Chat excelled in security-related tasks, with 76.5% of its generated code being free from vulnerabilities. These figures highlight the varying strengths of different LLMs and underscore the importance of selecting the right model for specific tasks. Furthermore, the framework demonstrated a 10% difference in performance when varying model parameters and a 9% difference when modifying prompts, showcasing the sensitivity of LLMs to these factors. The researchers also compared the results of LLMSecCode with those of reliable external actors, finding only a 5% difference, which attests to the framework’s accuracy and reliability.
In conclusion, the research conducted by the Chalmers University of Technology team presents LLMSecCode as a groundbreaking tool for evaluating the secure coding capabilities of LLMs. By providing a standardized assessment framework, LLMSecCode helps identify the most effective LLMs for secure coding, thereby contributing to the development of more secure software systems. The findings emphasize the importance of selecting the appropriate model for specific coding tasks and demonstrate that while LLMs have made significant strides in secure coding, there is still room for improvement and further research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.





: Build a Weather Agent with Python")




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment