



Large language models (LLMs) have emerged as powerful tools capable of performing complex tasks beyond text generation, including reasoning, tool learning, and code generation. These advancements have sparked significant interest in developing LLM-based language agents to automate scientific discovery processes. Researchers are exploring the potential of these agents to revolutionise data-driven discovery workflows across various disciplines. The ambitious goal is to create automated systems that can handle the entire research process, from generating ideas to conducting experiments and writing papers. However, this ambitious vision faces numerous challenges, including the need for robust reasoning capabilities, effective tool utilization, and the ability to navigate the complexities of scientific inquiry. The true capabilities of such agents remain a subject of excitement and skepticism within the research community.
Researchers from the Department of Computer Science and Engineering, OSU, College of Pharmacy, OSU, Department of Geography, UW–Madison, Department of Psychology, OSU, Department of Chemistry, UW–Madison, and Department of Biomedical Informatics, OSU present ScienceAgentBench, a robust benchmark designed to evaluate language agents for data-driven discovery. This comprehensive evaluation framework is built on three key principles: scientific authenticity, rigorous graded evaluation, and careful multi-stage quality control. The benchmark curates 102 diverse tasks from 44 peer-reviewed publications across four scientific disciplines, ensuring real-world relevance and minimizing the generalization gap. ScienceAgentBench employs a unified output format of self-contained Python programs, enabling consistent evaluation through various metrics examining generated code, execution results, and associated costs. The benchmark’s construction involves multiple rounds of validation by annotators and subject matter experts, with strategies implemented to mitigate data contamination concerns. This robust approach provides a more nuanced and objective assessment of language agents’ capabilities in automating scientific workflows. It offers valuable insights into their strengths and limitations in real-world scientific scenarios.
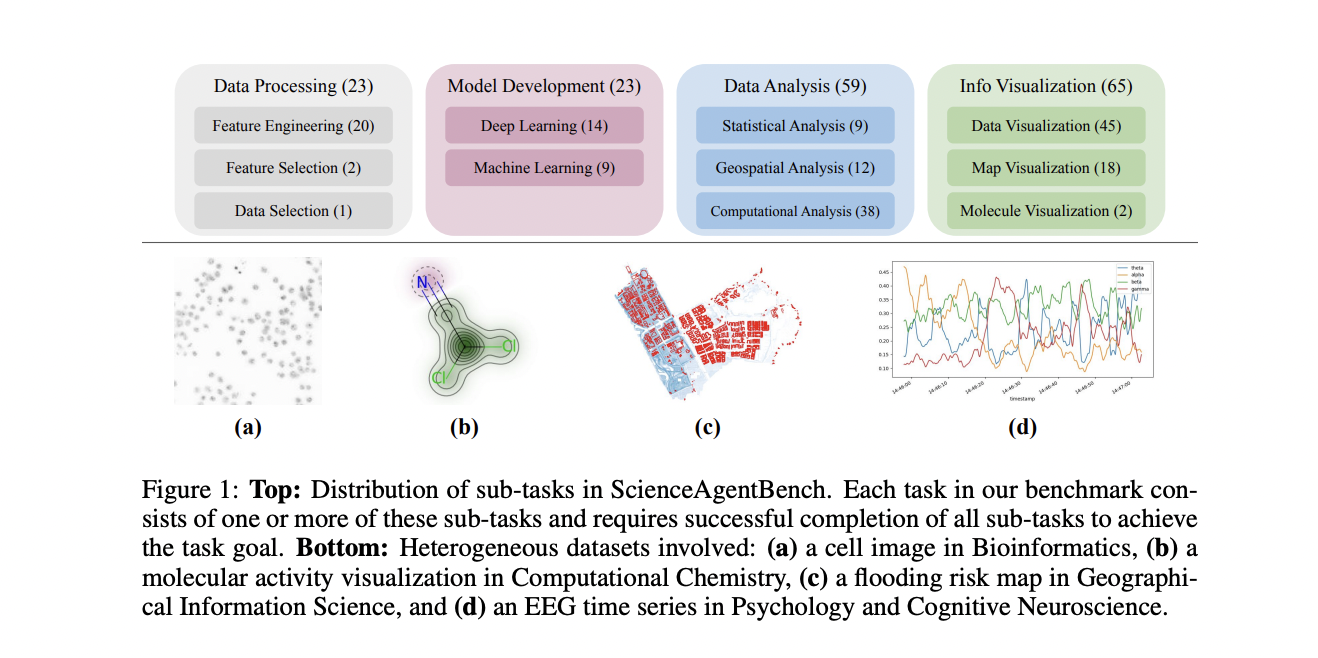

ScienceAgentBench is a comprehensive benchmark designed to evaluate language agents on essential tasks in data-driven discovery workflows. The benchmark formulates each task as a code generation problem, requiring agents to produce executable Python programs based on natural language instructions, dataset information, and optional expert-provided knowledge. Each task in ScienceAgentBench consists of four key components: a concise task instruction, dataset information detailing structure and content, expert-provided knowledge offering disciplinary context, and an annotated program adapted from peer-reviewed publications. The benchmark’s construction involved a meticulous process of task annotation, data contamination mitigation, expert validation, and annotator verification. To ensure authenticity and relevance, 102 diverse tasks were curated from 44 peer-reviewed publications across four scientific disciplines. ScienceAgentBench implements strategies to mitigate data contamination and prevent agents from taking shortcuts, including dataset modifications and test set manipulations. This rigorous approach ensures a robust evaluation framework for assessing language agents’ capabilities in real-world scientific scenarios.
The evaluation of language agents on ScienceAgentBench reveals several key insights into their performance in data-driven discovery tasks. Claude-3.5-Sonnet emerged as the top-performing model, achieving a success rate of 32.4% without expert knowledge and 34.3% with expert knowledge using the self-debug framework. This performance significantly outpaced direct prompting methods, which achieved only 16.7% and 20.6% success rates respectively. The self-debug approach proved highly effective, nearly doubling the success rate compared to direct prompting for Claude-3.5-Sonnet. Interestingly, the self-debug method also outperformed the more complex OpenHands CodeAct framework for most models, with Claude-3.5-Sonnet solving 10.8% more tasks at 17 times lower API cost. Expert-provided knowledge generally improved success rates and code-based similarity scores but sometimes led to decreased verification rates due to increased complexity in tool usage. Human evaluation corroborated these findings, showing clear distinctions between successful and failed programs, particularly in the data loading and processing stages. Despite these advancements, the results indicate that current language agents still struggle with complex tasks, especially those involving specialized tools or heterogeneous data processing in fields like Bioinformatics and Computational Chemistry.

ScienceAgentBench introduces a rigorous benchmark for evaluating language agents in data-driven scientific discovery. Comprising 102 real-world tasks from diverse scientific disciplines, the benchmark reveals the current limitations of language agents, with the best-performing model solving only 34.3% of tasks. This outcome challenges claims of full automation in scientific workflows and emphasizes the need for more robust evaluation methods. ScienceAgentBench serves as a crucial testbed for developing enhanced language agents, focusing on improving scientific data processing and knowledge utilization. It also paves the way for designing advanced automatic grading metrics, potentially incorporating LLM-based judges using task-specific rubrics.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
")




: Build a Weather Agent with Python")




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment