
: Build a Weather Agent with Python")


Generative modeling, particularly diffusion models (DMs), has significantly advanced in recent years, playing a crucial role in generating high-quality images, videos, and audio. Diffusion models operate by introducing noise into the data and then gradually reversing this process to generate data from noise. They have demonstrated significant potential in various applications, from creating visual artwork to simulating scientific data. However, despite their impressive generative capabilities, diffusion models suffer from slow inference speeds and high computational costs, which limits their practical deployment, particularly on devices with limited resources like smartphones.
One of the primary challenges in deploying diffusion models is their need for extensive computational resources and time during the generation process. These models rely on iterative steps to estimate and reduce noise in the data, often requiring thousands of iterations. This makes them inefficient for real-time applications, where speed and computational efficiency are essential. Furthermore, storing the large datasets needed to train these models adds another layer of complexity, making it difficult for many organizations to utilize diffusion models effectively. The problem becomes even more pressing as industries seek faster and more resource-efficient models for real-world applications.
Current methods to address the inefficiencies of diffusion models involve optimizing the number of denoising steps and the architecture of the neural networks used. Techniques like step reduction, quantization, and pruning are commonly applied to reduce the time required to generate data without compromising output quality. For example, reducing the number of steps during the noise reduction process can lead to faster results, while quantization helps minimize the precision requirements of the model, saving computational resources. Although these approaches improve efficiency to some extent, they often result in trade-offs concerning model performance, and there is still a significant need for solutions that can provide both speed and high-quality results.
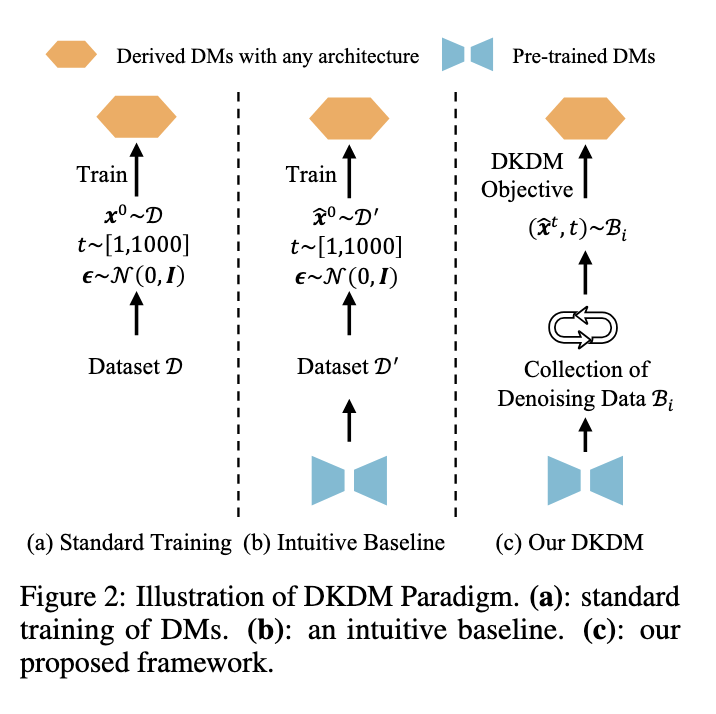
Researchers from the Harbin Institute of Technology and Illinois Institute of Technology have introduced a new solution known as Data-Free Knowledge Distillation for Diffusion Models (DKDM). This approach introduces a novel method for distilling the capabilities of large, pretrained diffusion models into smaller, more efficient architectures without relying on the original training data. This is particularly valuable when the original datasets are either unavailable or too large to store. The DKDM method allows for compressing diffusion models by transferring their knowledge to faster versions, thereby addressing the issue of slow inference speeds while maintaining model accuracy. The novelty of DKDM lies in its ability to work without access to the source data, making it a groundbreaking approach in the realm of knowledge distillation.
The DKDM method relies on a dynamic, iterative distillation process, which effectively generates synthetic denoising data through pretrained diffusion models, known as “teacher” models. This synthetic data is then used to train “student” models, which are smaller and faster than the teacher models. The process optimizes the student models using a specially designed objective function that closely mirrors the optimization goals of standard diffusion models. The synthetic data created by the teacher models simulates the noisy data typically produced during the reverse diffusion process, allowing the student models to learn efficiently without access to the original datasets. By employing this method, researchers can significantly reduce the computational load required for training new models while still ensuring that the student models retain the high generative quality of their teacher counterparts.
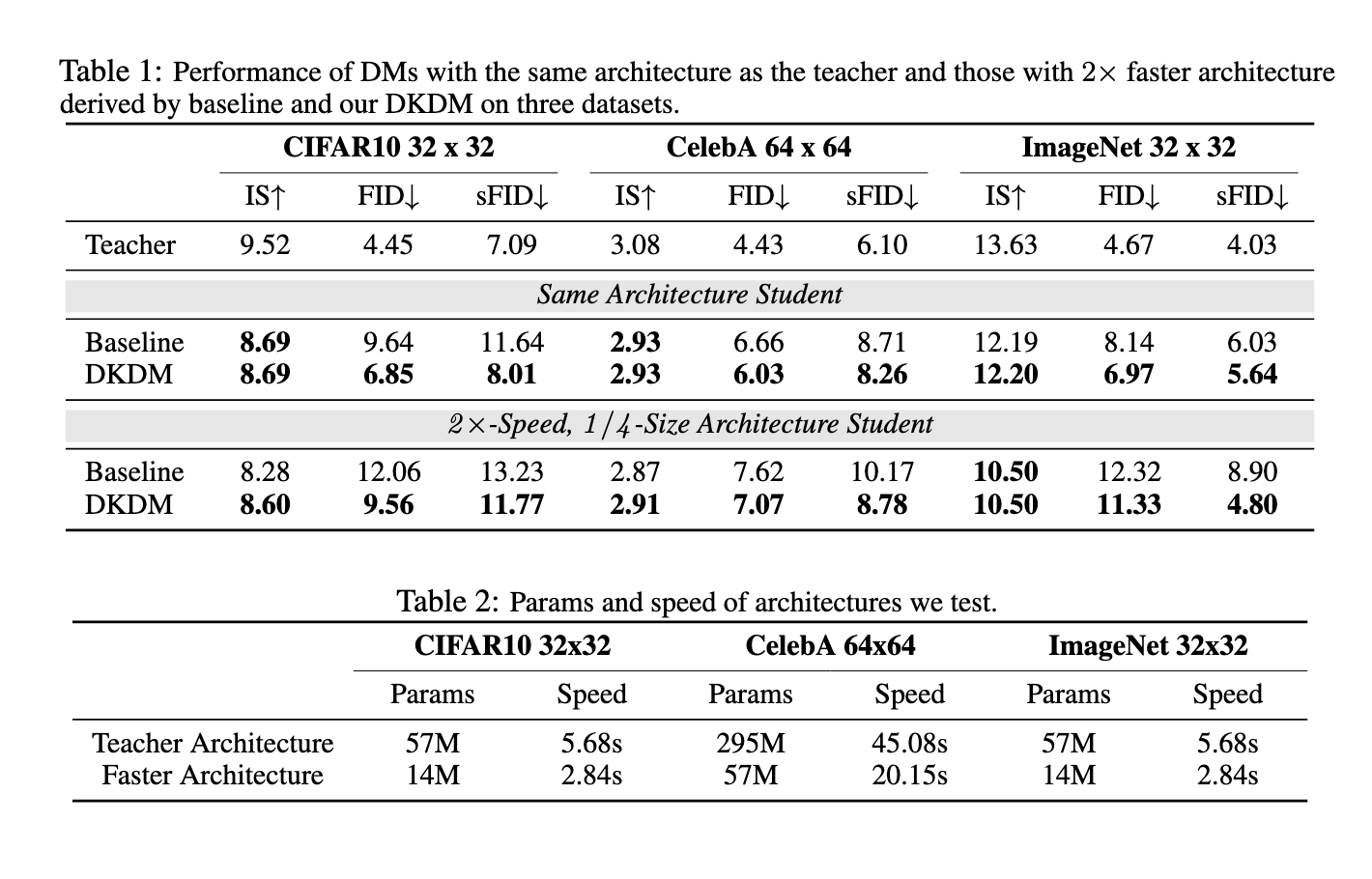
In experiments conducted by the research team, the DKDM approach demonstrated substantial performance improvements. Specifically, models trained using DKDM achieved generation speeds twice as fast as baseline diffusion models while maintaining nearly the same level of performance. For instance, when applied to the CIFAR-10 dataset, the DKDM-optimized student models achieved an Inception Score (IS) of 8.60 and a Fréchet Inception Distance (FID) score of 9.56, compared to the baseline scores of 8.28 IS and 12.06 FID. On the CelebA dataset, DKDM-trained models achieved a 2× speed improvement over baseline models with minimal impact on quality, as evidenced by a nearly identical IS of 2.91. Furthermore, DKDM’s flexible architecture allows it to integrate seamlessly with other acceleration techniques, such as quantization and pruning, further enhancing its practicality for real-world applications. Notably, these improvements were achieved without compromising the generative quality of the output, as demonstrated by the experiments on multiple datasets.
In conclusion, the DKDM method provides a practical and efficient solution to the problem of slow and resource-intensive diffusion models. By leveraging data-free knowledge distillation, the researchers from the Harbin Institute of Technology and Illinois Institute of Technology have developed a method that allows for faster, more efficient diffusion models without compromising on generative quality. This innovation offers significant potential for the future of generative modeling, particularly in areas where computational resources and data storage are limited. The DKDM approach successfully addresses the key challenges in the field and paves the way for more efficient deployment of diffusion models in practical applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.



: Build a Weather Agent with Python")






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment