



Generative models based on diffusion processes have shown great promise in transforming noise into data, but they face key challenges in flexibility and efficiency. Existing diffusion models typically rely on fixed data representations (e.g., pixel-basis) and uniform noise schedules, limiting their ability to adapt to the structure of complex, high-dimensional datasets. This rigidity results in inefficiencies, making the models computationally expensive and less effective for tasks requiring fine control over the generative process, such as high-resolution image synthesis and hierarchical data generation. Additionally, the separation between diffusion-based and autoregressive generative approaches has limited the integration of these methods, each of which offers distinct advantages. Addressing these challenges is essential for advancing generative modeling techniques in AI, as more adaptable, efficient, and integrated models are required to meet the growing demands of modern AI applications.
Traditional diffusion-based generative models, such as those by Ho et al. (2020) and Song & Ermon (2019), operate by progressively adding noise to data and then learning a reverse process to generate samples from noise. These models have been effective but come with several inherent limitations. First, they rely on a fixed basis for the diffusion process, typically using pixel-based representations that fail to capture multi-scale patterns in complex data. Second, the noise schedules are applied uniformly to all data components, ignoring the varying importance of different features. Third, the use of Gaussian priors limits the expressiveness of these models in approximating real-world data distributions. These constraints reduce the efficiency of data generation and hinder the models’ adaptability to diverse tasks, particularly those involving complex datasets where different levels of detail need to be preserved or prioritized.
Researchers from the University of Amsterdam introduced the Generative Unified Diffusion (GUD) framework to overcome the limitations of traditional diffusion models. This novel approach introduces flexibility in three key areas: (1) the choice of data representation, (2) the design of noise schedules, and (3) the integration of diffusion and autoregressive processes via soft-conditioning. By allowing diffusion to occur in different bases—such as the Fourier or PCA basis—the model can efficiently extract and generate features across multiple scales. Additionally, the introduction of component-wise noise schedules permits varying noise levels for different data components, dynamically adjusting to the importance of each feature during the generation process. The soft-conditioning mechanism further enhances the framework by unifying diffusion and autoregressive methods, allowing for partial conditioning on previously generated data and enabling more powerful, flexible solutions for generative tasks across diverse domains.
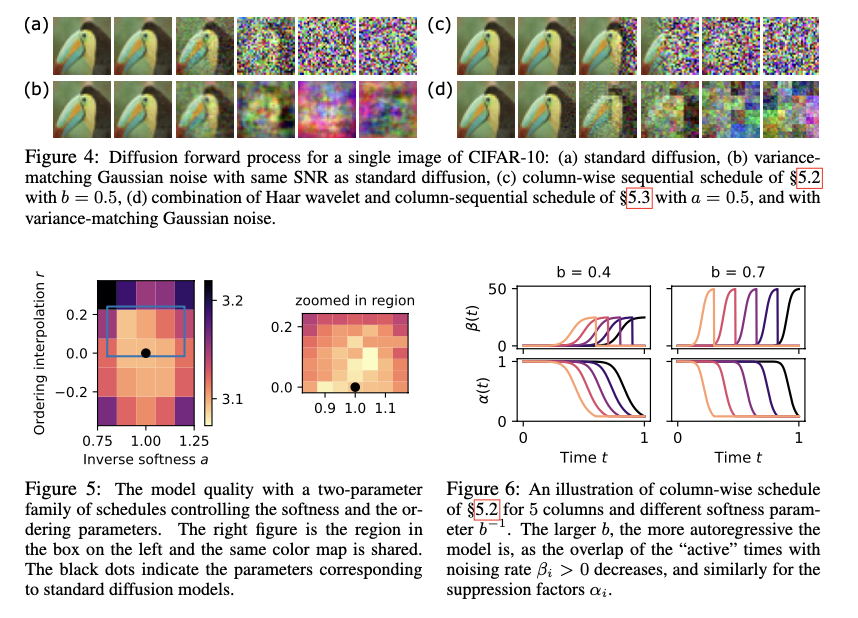
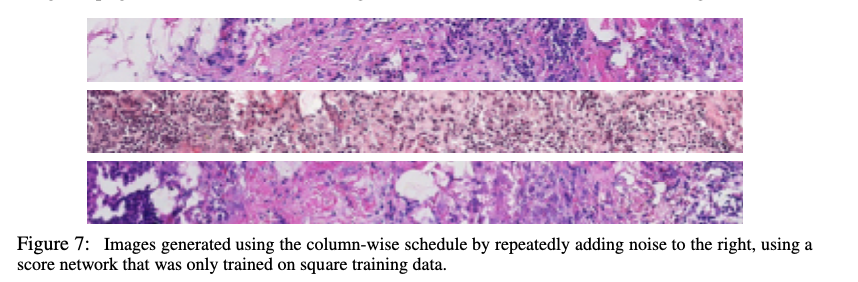
The proposed framework builds on the foundational stochastic differential equation (SDE) used in diffusion models but introduces a more general formulation that allows for flexibility in the diffusion process. The ability to choose different bases (e.g., pixel, PCA, Fourier) allows the model to better capture multi-scale features in the data, particularly in high-dimensional datasets like CIFAR-10. The component-wise noise schedule is a key feature, allowing the model to dynamically adjust the level of noise applied to different data components based on their signal-to-noise ratio (SNR). This enables the model to retain critical information in the data longer while diffusing less relevant parts more quickly. The soft-conditioning mechanism is particularly noteworthy, as it allows the generation of certain data components conditionally, bridging the gap between traditional diffusion and autoregressive models. This is achieved by allowing parts of the data to be generated based on information that has already been produced during the diffusion process, making the model more adaptable to tasks like image inpainting and hierarchical data generation.
The Generative Unified Diffusion (GUD) framework demonstrated superior performance across multiple datasets, significantly improving on key metrics such as negative log-likelihood (NLL) and Fréchet Inception Distance (FID). In experiments on CIFAR-10, the model achieved an NLL of 3.17 bits/dim, outperforming traditional diffusion models that typically score above 3.5 bits/dim. Additionally, the GUD framework’s flexibility in adjusting noise schedules led to more realistic image generation, as evidenced by lower FID scores. The ability to switch between autoregressive and diffusion-based approaches through the soft-conditioning mechanism further enhanced its generative capabilities, showing clear benefits in terms of both efficiency and the quality of generated outputs across tasks such as hierarchical image generation and inpainting.
In conclusion, the GUD framework offers a major advancement in generative modeling by unifying diffusion and autoregressive processes, and providing greater flexibility in data representation and noise scheduling. This flexibility leads to more efficient, adaptable, and higher-quality data generation across a wide range of tasks. By addressing key limitations of traditional diffusion models, this method paves the way for future innovations in generative AI, particularly for complex tasks that require hierarchical or conditional data generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.





: Build a Weather Agent with Python")




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment